

- Веб-пауки: хорошие и плохие
- Понимание бюджета сканирования
- Почему обход бюджета имеет значение?
- Определение вашего бюджета сканирования
- Как распределяется бюджет сканирования?
- Как: максимально использовать свой бюджет сканирования
- 1. Убедитесь, что важные страницы можно сканировать, а содержимое, которое не будет содержать значения,...
- 2. Избегайте длинных цепочек перенаправления.
- 3. Управление параметрами URL.
- 4. Найдите и исправьте ошибки HTTP.
- 5. Используйте RSS.
- 6. Держите вашу карту сайта в чистоте и актуальности.
- 7. Позаботьтесь о структуре вашего сайта и внутренних ссылок.

Автор: Евгений Хутарнюк , руководитель SEO, SEO PowerSuite
27 июня 2017

Бюджет сканирования - это одна из концепций SEO, которой не уделяется достаточного внимания. Многие из нас слышали об этом, но в основном мы склонны принимать бюджет сканирования как есть, предполагая, что нам была назначена определенная квота сканирования, на которую мы практически не влияем.
Или мы? Большинство веб-мастеров не должны сильно беспокоиться о скорости сканирования. Но если вы запускаете крупномасштабный веб-сайт, мы можем и должны оптимизировать бюджет сканирования для успеха SEO.
Конечно, поскольку дела обстоят с SEO, связь между бюджетом сканирования и рейтингом не является прямой. В январе 2017 года Google опубликовал сообщение в Центральном блоге для веб-мастеров, где поисковая система дала понять, что само сканирование не является фактором ранжирования. Но в некотором смысле бюджет сканирования важен для SEO.
В этом руководстве я расскажу вам о базовых концепциях, связанных со сканированием, о механизмах, с помощью которых поисковые системы назначают бюджеты сканирования веб-сайтам, а также о советах, которые помогут вам наилучшим образом использовать бюджет сканирования для максимизации рейтинга и органического трафика. ,
Веб-пауки: хорошие и плохие
Веб-пауки, сканеры или боты - это компьютерные программы, которые постоянно «посещают» и сканируют веб-страницы для сбора определенной информации о них и о них.
В зависимости от цели ползания можно выделить следующие типы пауков:
- Поисковые пауки,
- Пауки веб-сервисов,
- Хакерские пауки.
Поисковыми пауками управляют поисковые системы, такие как Google, Yahoo или Bing. Такие пауки загружают любые веб-страницы, которые они могут найти, и подают их в индекс поисковой системы.
Многие веб-сервисы, такие как инструменты SEO, магазины, путешествия и купонные сайты, имеют свои собственные веб-индексы и пауки. Например, WebMeUp есть паук по имени Blexbot. Blexbot сканирует до 15 миллиардов страниц ежедневно для сбора данных обратных ссылок и подачи этих данных в свой индекс ссылок (тот, который используется в SEO SpyGlass ).
Хакеры тоже разводят пауков. Они используют пауков для тестирования сайтов на различные уязвимости. Найдя лазейку, они могут попытаться получить доступ к вашему веб-сайту или серверу.
Вы можете слышать, как люди говорят о хороших и плохих пауках. Я различаю их таким образом: любые пауки, которые стремятся собирать информацию в незаконных целях, являются плохими. Все остальные хороши.
Большинство пауков идентифицируют себя с помощью строки пользовательского агента и предоставляют URL, где вы можете узнать больше о пауке:
- Mozilla / 5.0 (совместимо; Googlebot / 2.1; + http: //www.google.com/bot.html) или
- Mozilla / 5.0 (совместимо; BLEXBot / 1.0; + http: //webmeup-crawler.com/).
В этой статье я сосредоточусь на пауках поисковых систем и на том, как они сканируют веб-сайты.
Понимание бюджета сканирования
Бюджет сканирования - это количество случаев, когда паук поисковой системы посещал ваш сайт в течение определенного периода времени. Например, робот Googlebot обычно посещает мой сайт около 1000 раз в месяц, и я могу сказать, что 1K - это мой месячный бюджет сканирования для Google. Имейте в виду, что нет универсального ограничения на количество и частоту этих сканирований; мы рассмотрим факторы, которые формируют ваш бюджет обхода через минуту.
Почему обход бюджета имеет значение?
Логично, что вы должны быть обеспокоены бюджетом сканирования, потому что вы хотите, чтобы Google обнаружил как можно больше важных страниц вашего сайта. Вы также хотите, чтобы он быстро находил новый контент на вашем сайте. Чем больше ваш бюджет обхода (и чем умнее вы управляете им), тем быстрее это произойдет.
Определение вашего бюджета сканирования
Вы можете получить представление о бюджете сканирования вашего сайта в Google Search Console а также Инструменты Bing для веб-мастеров , Данные сканирования, которые вы получите в этих инструментах, являются очень общими, но достаточными для этого шага.
Допустим, вам нужно определить свой бюджет сканирования Google. Войдите в свою учетную запись Консоли поиска и перейдите в Сканирование -> Статистика сканирования . Здесь вы увидите среднее количество страниц вашего сайта, просканированных за день.
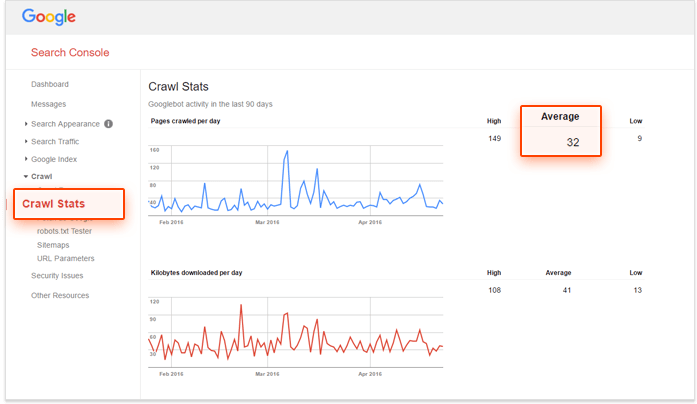
Из приведенного выше отчета видно, что в среднем Google сканирует 32 страницы моего сайта в день. Исходя из этого, я могу понять, что мой ежемесячный бюджет обхода составляет 32 * 30 = 960.
Конечно, это число подвержено изменениям и колебаниям. Но это даст вам четкое представление о том, сколько страниц вашего сайта можно будет сканировать за определенный период времени.
Если вам нужна более подробная разбивка статистики сканирования по отдельным страницам, вам придется проанализировать следы пауков в журналах сервера. Расположение файлов журнала зависит от конфигурации сервера. Apache обычно хранит их в одном из следующих мест:
/ Вар / Журнал / HTTPD / access_log
/var/log/apache2/access.log
/var/log/httpd-access.log
Если вы не уверены, как получить доступ к журналам сервера, обратитесь за помощью к системному администратору или хостинг-провайдеру.
Необработанные файлы журнала трудно читать и анализировать. Чтобы понять это, вам понадобится уровень джедая. регулярные выражения навыки или специализированные инструменты. Я предпочитаю использовать WebLogExpert (у них есть 30-дневная пробная версия).
Как распределяется бюджет сканирования?
Что касается SEO, мы точно не знаем, как поисковые системы формируют бюджет сканирования для сайтов. По данным Google, поисковая система учитывает два фактора для определения бюджета сканирования:
- Популярность - более популярные страницы сканируются чаще, и
- Устаревание - Google не позволяет устаревшей информации о страницах. Для веб-мастеров это означает, что если контент страницы часто обновляется, Google пытается сканировать страницу чаще.
Похоже, Google использует термин популярность, чтобы заменить устаревший PageRank.
Еще в 2010 году Мэтт Каттс из Google сказал по этому поводу следующее:
Msgstr "Количество страниц, которые мы сканируем, примерно пропорционально вашему PageRank".
Хотя PageRank больше не обновляется публично, все еще можно предположить, что бюджет сканирования сайта в значительной степени пропорционален количеству обратных ссылок и важности сайта в глазах Google - логично, что Google стремится обеспечить, чтобы самые важные страницы оставались самый свежий в своем индексе.
А как насчет внутренних ссылок? Можете ли вы увеличить скорость сканирования определенной страницы, указав на нее больше внутренних ссылок?
Чтобы ответить на эти вопросы, я решил проверить соотношение между внутренними и внешними ссылками и статистикой сканирования. Я собрал данные для 11 сайтов и провел простой анализ. Вкратце, вот что я сделал.
Анализ
С Аудитор сайта Я создал проекты для 11 сайтов, которые собирался проанализировать. Я подсчитал количество внутренних ссылок, указывающих на каждую страницу каждого из этих сайтов. Далее я побежал SEO Spyglass и создал проекты для тех же 11 сайтов. В каждом проекте я проверял статистику и копировал URL-адреса привязки с количеством внешних ссылок, указывающих на каждую страницу. Затем я проанализировал статистику сканирования в журналах сервера, чтобы увидеть, как часто робот Googlebot посещает каждую страницу. Наконец, я поместил все эти данные в электронную таблицу и рассчитал соотношение между внутренними ссылками и бюджетом сканирования, а также внешними ссылками и бюджетом сканирования.
Я нашел что-то довольно интересное. Вот пример электронной таблицы для одного из сайтов, которые я проанализировал:
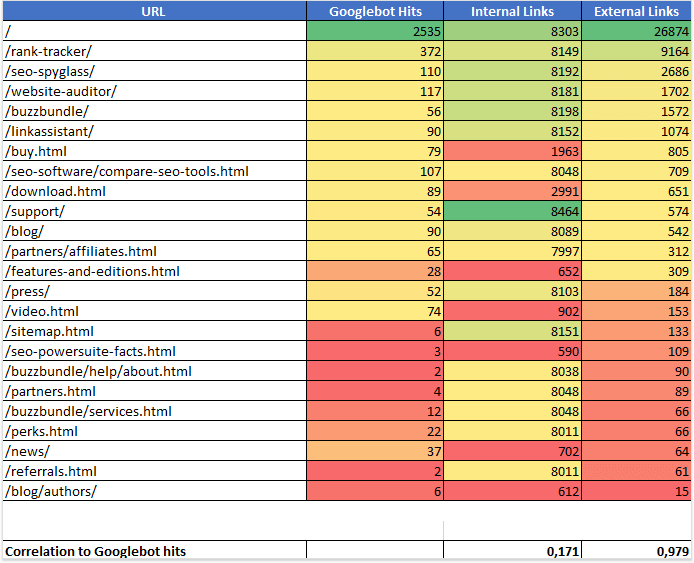
Мой набор данных доказал, что существует сильная корреляция (0,978) между количеством посещений паука и количеством внешних ссылок. В то же время корреляция между попаданиями паука и внутренними связями оказалась очень слабой (0,154). Это показывает, что обратные ссылки гораздо важнее для сканирования сайта, чем внутренние ссылки.
Означает ли это, что единственный способ увеличить ваш бюджет сканирования - это создавать ссылки и публиковать свежий контент? Если мы говорим о бюджете для всего вашего сайта, я бы сказал, да: увеличьте свой профиль ссылок и часто обновляйте сайт, и бюджет сканирования вашего сайта будет пропорционально расти. Но когда мы берем отдельные страницы, вот где это становится интересным. Как вы узнаете из инструкций ниже, вы можете тратить большую часть своего бюджета на обход, даже не осознавая этого. Умно управляя своим бюджетом, вы часто можете удвоить количество просмотров для отдельных страниц, но оно все равно будет пропорционально количеству обратных ссылок на каждой странице.
Как: максимально использовать свой бюджет сканирования
Теперь, когда мы выяснили, что сканирование важно для индексации, не пора ли сосредоточиться на лучших способах управления бюджетом сканирования для максимальной радости SEO?
Есть довольно много вещей, которые вы должны (или не должны) делать, чтобы поисковые пауки занимали больше страниц вашего сайта и делали это чаще. Вот список действий для максимизации эффективности вашего бюджета сканирования:
1. Убедитесь, что важные страницы можно сканировать, а содержимое, которое не будет содержать значения, если оно найдено в поиске, заблокировано.
Ваши .htaccess и robots.txt не должны блокировать важные страницы сайта, и боты должны иметь возможность доступа к файлам CSS и Javascript. В то же время вы можете и должны блокировать контент, который вы не хотите показывать в поиске. Лучшими кандидатами на блокировку являются страницы с дублированным контентом, «незавершенными» областями веб-сайта, динамически генерируемыми URL-адресами и т. Д.
Аудитор сайта отлично подходит для создания и управления файлами robots.txt.
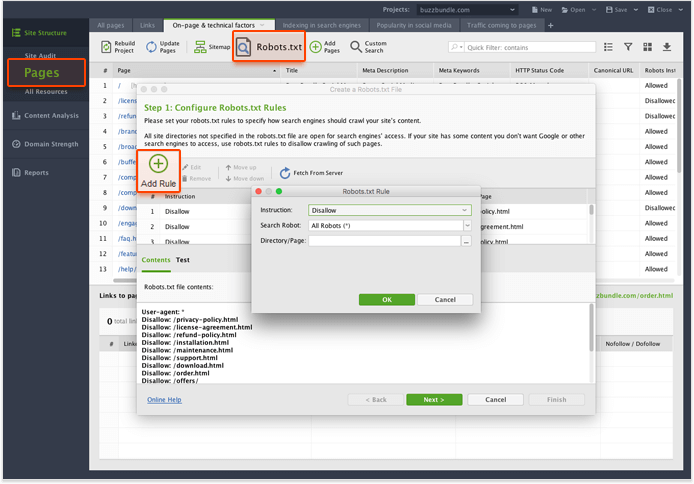
Вот краткое руководство:
- Запустите инструмент (если у вас все еще нет Аудитора веб-сайта, вы можете скачать бесплатно здесь ) и создайте или откройте проект.
- Перейдите на вкладку « Страницы » и щелкните значок Robots.txt . Вы увидите текущее содержимое вашего файла robots.txt.
- Чтобы добавить новое правило в ваш файл robots.txt, нажмите Добавить правило . Программное обеспечение позволит вам выбрать инструкцию ( Запретить или Разрешить ), паука (вы можете ввести его имя вручную или выбрать из списка наиболее распространенных поисковых роботов), а также URL-адрес или каталог, который необходимо заблокировать.
- Точно так же вы можете удалять и редактировать существующие правила.
- Когда вы закончите редактирование, нажмите « Далее» и либо сохраните файл на жестком диске, либо загрузите его на свой сайт через FTP прямо сейчас.
Вернувшись в модуль « Страницы », вы также получите множество статистических данных о сканировании, таких как дата кэширования для Google, Bing и Yahoo, инструкции robots.txt и код состояния HTTP.
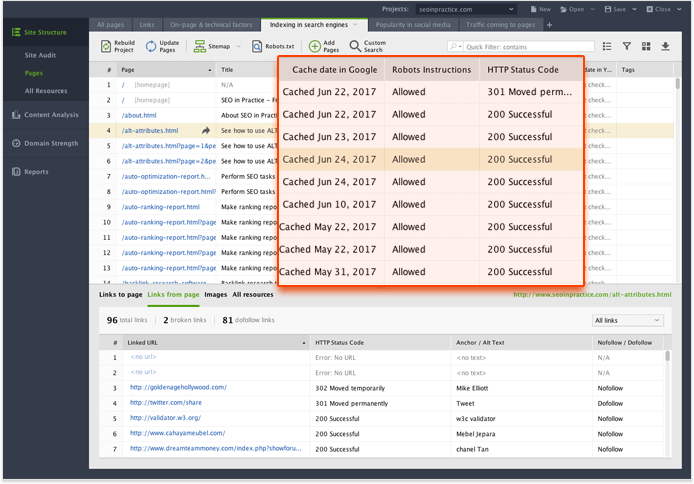
 Имейте в виду, что пауки поисковых систем не всегда соблюдают инструкции, содержащиеся в robots.txt. Вы когда-нибудь видели такой фрагмент в Google?
Имейте в виду, что пауки поисковых систем не всегда соблюдают инструкции, содержащиеся в robots.txt. Вы когда-нибудь видели такой фрагмент в Google?

Хотя эта страница заблокирована в robots.txt, Google знает об этом. Он не кэширует его и не создает для него стандартный фрагмент. Тем не менее, он иногда попадает в него. Вот что говорит Google по этому вопросу:
Robots.txt Disallow не гарантирует, что страница не будет отображаться в результатах: Google по-прежнему может на основании внешней информации, такой как входящие ссылки, принять решение о ее релевантности. Если вы хотите явно заблокировать индексацию страницы, вам следует использовать метатег noindex robots или HTTP-заголовок X-Robots-Tag. В этом случае вам не следует запрещать страницу в robots.txt, потому что страница должна быть просканирована, чтобы тег можно было увидеть и повиноваться.
Кроме того, если вы запрещаете большие области своего веб-сайта, блокируя папки или используя подстановочные знаки, робот Google может предположить, что вы сделали это по ошибке, и по-прежнему сканировать некоторые страницы из закрытых областей.
Поэтому, если вы пытаетесь сэкономить бюджет сканирования и заблокировать отдельные страницы, которые не считаете важными, используйте файл robots.txt. Но если вы не хотите, чтобы Google знал о странице вообще - использовать метатеги ,
2. Избегайте длинных цепочек перенаправления.
Если на вашем сайте есть необоснованное количество перенаправлений 301 и 302, поисковые пауки в какой-то момент перестанут следовать за перенаправлениями, и страница назначения может не просканироваться. Более того, каждый перенаправленный URL является пустой тратой «единицы» вашего бюджета сканирования. Убедитесь, что вы используете перенаправления не более двух раз подряд и только тогда, когда это абсолютно необходимо.
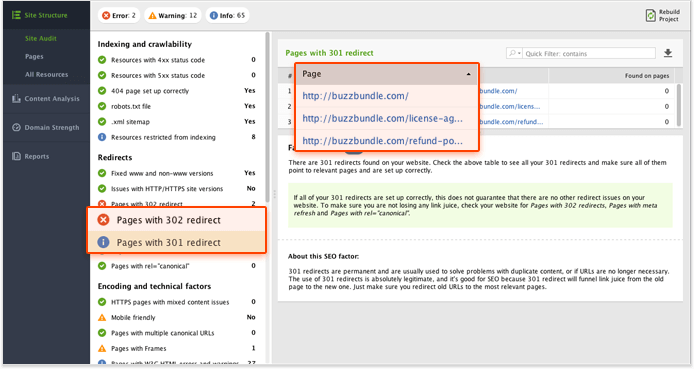
Вы можете получить полный список страниц с перенаправлениями в WebSite Auditor ,
- Откройте свой проект и перейдите в модуль Аудит сайта .
- Нажмите « Страницы с перенаправлением 302» и « Страницы с перенаправлением 301», чтобы увидеть полный список перенаправленных страниц.
- Нажмите на Страницы с длинными цепями перенаправления, чтобы получить список URL с более чем двумя перенаправлениями.
3. Управление параметрами URL.
Популярные системы управления контентом генерируют множество динамических URL, которые фактически ведут на одну и ту же страницу. По умолчанию роботы поисковых систем обрабатывают эти URL-адреса как отдельные страницы; в результате вы можете не только тратить свой бюджет на сканирование, но и потенциально опасаться дублирования контента.
Если движок вашего веб-сайта или CMS добавляет параметры к URL-адресам, которые не влияют на содержание страниц, убедитесь, что вы сообщили об этом роботу Google, добавив эти параметры в свою учетную запись консоли поиска Google в разделе Сканирование -> Параметры URL-адреса .
4. Найдите и исправьте ошибки HTTP.
Любой URL, который получает Google, включая CSS и Java Script, потребляет одну единицу вашего бюджета сканирования. Вы не хотите тратить его на 404 или 503 страницы, не так ли? Найдите минутку, чтобы проверить ваш сайт на наличие неработающих ссылок или ошибок сервера, и исправьте их как можно скорее.
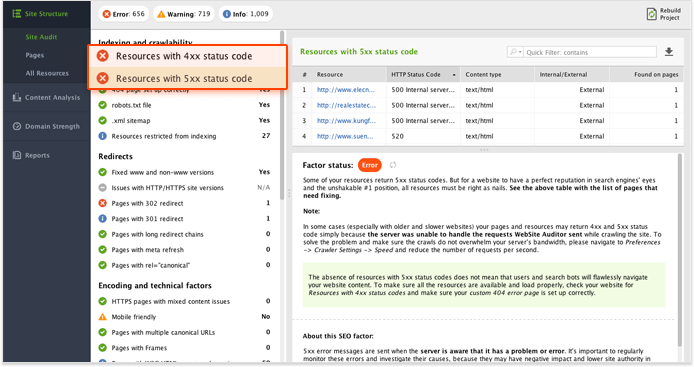
- В своем проекте «Аудитор веб- сайта» выберите «Структура сайта»> «Аудит сайта» .
- Нажмите на коэффициент неработающих ссылок . На правой панели вы увидите список неработающих ссылок на вашем сайте, которые нужно исправить, если таковые имеются.
- Затем нажмите Ресурсы с кодом состояния 4xx и Ресурсы с кодом статуса 5xx, чтобы получить список ресурсов, которые возвращают ошибки HTTP.
5. Используйте RSS.
Из того, что я наблюдаю, RSS-каналы являются одними из самых посещаемых страниц Google Spider. Если определенный раздел на вашем веб-сайте часто обновляется (блог, страница рекомендуемых продуктов, раздел новых поступлений), обязательно создайте для него RSS-канал и отправьте его в Google. Горелка подачи , Не забудьте сохранить RSS-каналы свободными от неканонических, заблокированных от индексации или 404 страниц.
6. Держите вашу карту сайта в чистоте и актуальности.
XML-карты сайта важны для правильного сканирования сайта. Они сообщают поисковым системам об организации вашего контента и позволяют поисковым роботам быстрее находить новый контент. Ваша карта сайта XML должна регулярно обновляться и быть свободной от мусора (страницы 4хх, неканонические страницы, URL-адреса, перенаправляющие на другие страницы, и страницы, заблокированные от индексации).
Вы можете получить список таких URL-адресов в Аудитор сайта и легко исключить их из вашей карты сайта.
- В своем проекте WebSite Auditor перейдите к модулю Site Audit .
- Нажмите на Страницы с кодом статуса 4xx, чтобы получить список страниц 4xx, если таковые имеются. Скопируйте URL-адреса в отдельный файл (подойдет электронная таблица или любой обычный текстовый редактор).
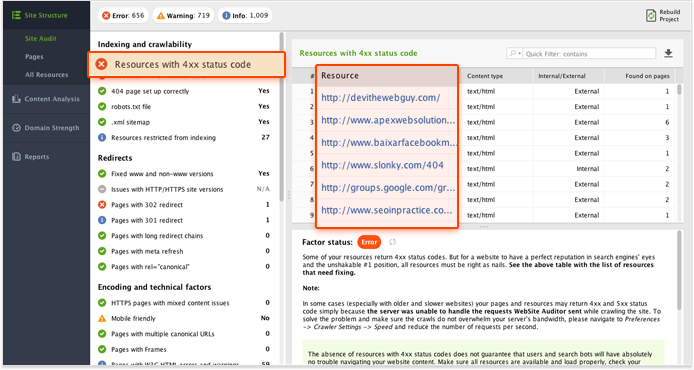
- Нажмите на Страницы с перенаправлением 301 для списка 301 страниц. Скопируйте их тоже.
- Сделайте то же самое для страниц с перенаправлением 302 .
- Нажмите на Страницы с rel = 'canonical', чтобы получить список канонических и неканонических страниц. Добавьте эти URL в свой список.
Веб-сайт Auditor также имеет удобный генератор XML Sitemap. Просто нажмите на файл Sitemap, чтобы начать создавать свою карту сайта XML.
- Используйте быстрый фильтр, чтобы найти 4xx, 3xx и неканонические URL, которые вы только что скопировали, и снимите флажки рядом с этими страницами.
- Отрегулируйте приоритет и измените частоту . Эти параметры не являются обязательными, но они могут помочь вам направить поисковых роботов на более важные и часто обновляемые страницы вашего сайта. Например, вы обычно отдает наивысший приоритет своей домашней странице, затем страницам категорий, а затем подкатегориям.
Частота изменения описывает частоту обновления вашей страницы, чтобы дать сканерам и представление о том, когда каждая страница или каталог может измениться, и что к нему следует вернуться снова.
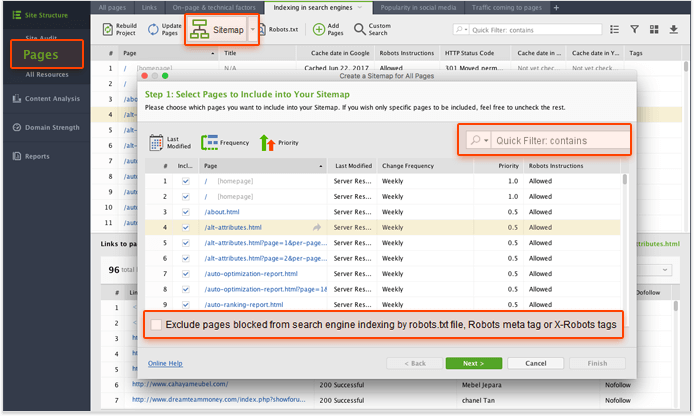
Если вы работаете с большим веб-сайтом, который имеет много подразделов, полезно создать отдельную карту сайта для каждого подраздела. Это упростит управление картой сайта и позволит быстро определить области сайта, где возникают проблемы с сканированием. Например, у вас может быть карта сайта для доски обсуждений, другая карта сайта для блога и еще одна карта сайта для основных страниц сайта. Для веб-сайтов электронной коммерции целесообразно создавать отдельные карты сайтов для крупных категорий продуктов.
Убедитесь, что все карты сайта обнаружены пауками. Вы можете включить ссылки на карты сайта в robots.txt и зарегистрировать их в консоли поиска.
7. Позаботьтесь о структуре вашего сайта и внутренних ссылок.
Хотя внутренние ссылки не имеют прямой корреляции с бюджетом сканирования, структура сайта по-прежнему является важным фактором, позволяющим сделать ваш контент доступным для поиска поисковым роботам. Логическая древовидная структура веб-сайта имеет много преимуществ, таких как взаимодействие с пользователем и количество времени, которое ваши посетители будут проводить на вашем сайте, и улучшенное сканирование - одно из них.
В целом, поддержание важных областей вашего сайта на расстоянии не более 3-х кликов от любой страницы - хороший совет. Включите наиболее важные страницы и категории в меню вашего сайта или нижнего колонтитула. Для более крупных сайтов, таких как блоги и веб-сайты электронной коммерции, разделы со связанными публикациями / продуктами и избранными публикациями / продуктами могут помочь в размещении целевых страниц - как для пользователей, так и для роботов поисковых систем.
Если вам нужны подробные инструкции, я настоятельно рекомендую вам пройти через это руководство по внутренним ссылкам ,
Как видите, SEO - это не только «ценный контент» и «авторитетные ссылки». Когда передняя сторона вашего сайта выглядит отшлифованной, может быть, пора спуститься в погреб и заняться охотой на пауков - она наверняка сотворит чудеса в улучшении эффективности вашего сайта в поиске.
Теперь, когда у вас есть все необходимые инструменты и знания для приручения пауков в поисковых системах, продолжайте тестировать их на своем собственном сайте и, пожалуйста, поделитесь результатами в комментариях!
PS: О, и вот милый паук, чтобы украсить ваш день:

Автор: Евгений Хутарнюк
Руководитель SEO в SEO PowerSuite
Похожие
Что такое SEO Как мне использовать это умно как предприниматель?Что такое SEO SEO расшифровывается как «Поисковая оптимизация» или: поисковая оптимизация. Это означает, что вы улучшаете свой веб-сайт, чтобы вас лучше находили в поисковых системах, таких как Google. Другими словами: вы можете использовать SEO для большей популярности вашего сайта, а для большего количества посетителей, которые становятся клиентами, оставьте Основы SEO: оптимизация внутренних ссылок
... сайта. Сайты могут получить высокий рейтинг даже без внешних ссылок В действительности, мы видим, что многим сайтам удается получить очень сильный рейтинг, даже не имея внешних ссылок. Это, очевидно, намного проще сделать для длинного хвоста, чем для оспариваемых ключевых слов, но большинство ключевых слов являются частью длинного хвоста, и, в целом, многие сэкономленные пенни - это довольно много заработанных копеек. Я также знаю много дополнительных Исправьте 404 ошибки, чтобы улучшить пользовательский опыт и SEO
Вам нужно исправить 404 ошибки на вашем сайте WordPress? В какой-то момент это случилось со всеми нами - вы щелкаете ссылку и в итоге получаете страницу « 404 - Страница не найдена ». Что ты будешь делать дальше? Вы щелкаете прочь, верно? Что такое время загрузки страницы и почему это важно?
Сегодня так много сайтов у них под рукой Sky Rocket Ваш SEO с оптимизацией скорости страницы
... имизированы производительность и скорость страницы вашего сайта? Не многие компании принимают это во внимание, и при запуске нового веб-сайта не исключено, что визуальный дизайн, эстетика и изящная функциональность имеют приоритет над производительностью. Люди любят быстрые веб-сайты в 2018 году и, собственно, и Google, которые указали, что скорость страницы будет влиять на рейтинг в поисковых SEO не работает
Это выглядит как смелое утверждение: поисковая оптимизация (SEO) не работает. Но, к сожалению, подавляющее большинство того, что выдавалось за SEO, на самом деле является SEO старой школы - вещи, которые работали 5 и 10 лет назад, но сейчас полностью устарели. Старая школа SEO не только не работает, но и часто приводит к обратным результатам. Назад, когда Ларри Пейдж Создание перенаправлений - какие есть варианты?
... сайтах. Например, если веб-сайт вашего местного города ссылается на Торговую палату в этом районе, они могут использовать мета-обновление с задержкой в 5-10 секунд. Когда пользователь щелкает эту ссылку, он попадает на страницу, которая говорит что-то вроде: «Вы перенаправлены на внешний контент; мы не можем нести ответственность за содержимое этого сайта ». Пользователь кратко просматривает это уведомление, а затем перенаправляется на внешнюю страницу. Очень немногие 301 и 302 перенаправления - как перенаправления страниц влияют на SEO
Переадресация страниц - это повседневная часть веб-серфинга, и, за исключением странного 404 не найденного места назначения, средний пользователь интернета почти не замечает их. Это в значительной Инструкция по обновлению контента в Joomla 1.5
Нажмите на ссылку ниже, чтобы легко следовать инструкциям о том, как: Ищете инструкции Joomla 2.5? Кликните сюда: Как обновить содержимое вашего сайта Joomla 2.5 Как войти на свой сайт Откройте веб-браузер Перейти Как создать SEO-стратегию за 5 шагов?
... ит до стартап-маркетинга, оптимизация сайта для Google - одна из первых вещей, которая приходит на ум. Сегодня конкуренция настолько жесткая, что простого веб-сайта недостаточно, чтобы привлечь внимание. Вот тут-то и проскакивает контент-маркетинг и бизнес-блоги. С контент-маркетингом становится намного легче выделиться и оставить свой след. Поисковая оптимизация, т.е. SEO - это метод, используемый для ранжирования страниц сайта в поисковых системах. Цель состоит в том, чтобы ранжировать Создать карту сайта, отправить и использовать для SEO
Sitemap-all-inclusive-package для всех SEO-новичков находится здесь: Что такое карта сайта? Как я могу создать карту сайта ? Какие инструменты помогают мне? Какое значение это имеет для поисковых систем и поисковой оптимизации? Интеграция карты сайта в работу на вашем собственном веб-сайте - не очень сложная задача, если вы понимаете функцию файла sitemap.xml. Многие веб-сайты уже имеют карту сайта, только операторы не знают, как и как они могут ее использовать.
Комментарии
А как насчет нейтральных, которые не помогают, но не влияют на рейтинг вашего сайта и SEO?А как насчет нейтральных, которые не помогают, но не влияют на рейтинг вашего сайта и SEO? Нейтральные обратные ссылки могут не дать вашему веб-сайту необходимую поддержку SEO, но они также не будут подвергать ваш сайт потенциально суровым штрафам Google. Фактически, с обновлением Google Penguin, некоторые штрафы за плохие обратные ссылки, потому что поисковая система поняла, что сами сайты не имеют контроля над каждым сайтом, который ссылается на их. В результате, Не знаете, что такое файлы журналов или почему и как они могут быть важны для повышения вашей органической производительности?
Не знаете, что такое файлы журналов или почему и как они могут быть важны для повышения вашей органической производительности? Пожалуйста, проверьте наше подробное руководство , Хорошо, так что с введениями давайте застрянем в ... Начиная Настройка сайта для сканирования упрощается за 4 простых шага, второй из которых включает возможность подключения данных из различных источников: Почему архитектура сайта имеет значение?
Почему архитектура сайта имеет значение? Существуют различные преимущества, которые вы получите от правильной архитектуры сайта. Улучшенный рейтинг в поисковых системах Хотите определить, как страницы вашего сайта отображаются в Google?
Хотите определить, как страницы вашего сайта отображаются в Google? Тогда используйте SEO от Yoast , Вернуться к обзору Вы уже создаете контент для блога своего бизнеса, так почему бы не потратить немного времени на создание лучшего контента, который поможет ранжированию вашего сайта в Google?
Вы уже создаете контент для блога своего бизнеса, так почему бы не потратить немного времени на создание лучшего контента, который поможет ранжированию вашего сайта в Google? РЕАЛЬНАЯ ЖИЗНЬ. РЕАЛЬНЫЕ НОВОСТИ. РЕАЛЬНЫЕ ГОЛОСА. Помогите нам рассказать больше историй, которые имеют значение от голосов, которые слишком часто остаются неуслышанными. Почему это имеет значение для вашего бренда?
Почему это имеет значение для вашего бренда? Мы помогаем брендам использовать появляющиеся возможности и проверенные методы, чтобы быть лидерами рынка и приносить ощутимые результаты. Конкурировать и побеждать в современной социальной и цифровой экономике Ваш бизнес или бренд работают в цифровой, социальной экономике - с или без вашего участия. Мы являемся мастерами в полной мере использовать отношения между собственными, заработанными и платными медиа для оптимальной Но не будет ли это более эффективным и справедливым, чем то, что Google присваивает нулевой вес всем ссылкам, которые были определены как приобретенные?
Но не будет ли это более эффективным и справедливым, чем то, что Google присваивает нулевой вес всем ссылкам, которые были определены как приобретенные? На стороне Interflora UK команда активно очищает все это и, в частности, удаляет обратные ссылки. Будем надеяться, что они не совершат ошибок, удалив обратные ссылки, которые Google не определил как «фиктивные», иначе это будет немного больше, чем их ссылки на Google. Они, вероятно, также попробуют путь Значит ли это, что мы думаем, что вам не следует использовать файлы Sitemap для видео?
Значит ли это, что мы думаем, что вам не следует использовать файлы Sitemap для видео? Нет. Мы считаем, что всякий раз, когда вы можете отправлять информацию напрямую в Google о своем сайте через файл Sitemap, это будет полезно. При этом прямо сейчас мы не видим различий между двумя, но мы также видим почти немедленную индексацию и отображение миниатюры видео рядом с нашими списками в Google. Например, на нашем Плагин сделок Страница, Как вы можете увеличить количество бронирований и увеличить продажи с вашего туристического сайта?
Как вы можете увеличить количество бронирований и увеличить продажи с вашего туристического сайта? Как вы можете гарантировать стабильный рост вашего туристического бизнеса? Ответ через SEO путешествий. SEO для путешествий не является теоретической концепцией, но это термин, используемый для описания набора шагов, которые вы можете выполнить, чтобы оптимизировать свой сайт для поисковых систем. Почему SEO путешествий важно? Если у вас есть туристический сайт или блог, Они могут использовать различные тактики негативного SEO, чтобы ваша страница не получила хорошего рейтинга, а вы этого не хотите?
Они могут использовать различные тактики негативного SEO, чтобы ваша страница не получила хорошего рейтинга, а вы этого не хотите? Рассерженные клиенты, злые конкуренты - будьте добры ко всем и сделайте все возможное, чтобы не дать другим поводов отомстить вам. Конечно, всегда есть люди, которые спамят ради этого, и с такими людьми нет никаких рассуждений. В таких ситуациях вам просто нужно иметь лучшую защиту от таких негативных SEO-атак. А еще лучше, нанять SEO-консультантов, которые Как насчет высококачественных страниц, где каждая страница оптимизирована для конкретного ключевого слова - будет ли этот тип страницы рассматриваться как страница дорвея?
Как насчет высококачественных страниц, где каждая страница оптимизирована для конкретного ключевого слова - будет ли этот тип страницы рассматриваться как страница дорвея? Подумайте о следующем примере - Компания Виджета Джо продает сотни различных типов Виджетов по всей Южной PA. Сайт Джо имеет отличный уникальный контент, но его компания невелика по сравнению с его конкурентами, находящимися в международной собственности, которые обслуживают всю
Или мы?
Почему обход бюджета имеет значение?
Как распределяется бюджет сканирования?
А как насчет внутренних ссылок?
Можете ли вы увеличить скорость сканирования определенной страницы, указав на нее больше внутренних ссылок?
Означает ли это, что единственный способ увеличить ваш бюджет сканирования - это создавать ссылки и публиковать свежий контент?
Вы когда-нибудь видели такой фрагмент в Google?
Вы не хотите тратить его на 404 или 503 страницы, не так ли?
Что ты будешь делать дальше?
Вы щелкаете прочь, верно?