

- Что такое веб-сканеры?
- Почему они ценны?
- Что является недостатком?
- Как на самом деле работают веб-сканеры?
- Что это действительно означает технически?
- Что ждет будущее веб-сканирования?
- Куда я иду отсюда?
- Как я могу контролировать веб-сканеры с Robots.txt?
- Создание или редактирование файла Robots.txt
- На вашем сайте:
- На вашем сервере:
- Управление доступом Web Crawler через файл Robots.txt
- Примеры использования Robots.txt:
- Чтобы разрешить полный доступ всем сканерам:
- Чтобы запретить всем сканерам обход нескольких каталогов или страниц:
- Чтобы исключить одного сканера:
- Чтобы разрешить доступ только одному роботу:
- Как управлять веб-сканерами с помощью метатега роботов?
- Чтобы запретить всем сканерам индексировать страницу:
- Чтобы запретить сканерам следующие ссылки на странице:
- Чтобы запретить сканерам сканировать и индексировать страницу и последующие страницы, на которые она...
- Чтобы поисковые системы не кэшировали вашу страницу:
- Чтобы проиндексировать и перейти на страницу:
- Как управлять веб-сканерами без какой-либо кодировки

Как показывает преобладание Google , в Интернете, а точнее во всемирной паутине, преобладают наличие и использование сканеров. В частности, это программы, которые ищут, индексируют и оценивают различные существующие веб-сайты. Короче говоря, они говорят нам, куда идти, когда мы ищем определенное слово или фразу.
Тем не менее, большинство людей не знают, как они достигают этой цели. Вот исчерпывающее руководство по поисковым роботам и их управлению через файл robots.txt, теги meta robot и наш плагин - SEOPressor Connect :
Что такое веб-сканеры?

Сканеры известны под разными именами - отраслевой жаргон называет их пауками или ботами, но технически они называются веб-сканерами .
Независимо от названия, они используются для сканирования в Интернете, «читая» все, что они находят. В частности, они индексируют, какие слова используются на веб-сайте и в каком контексте. Созданный индекс - это в основном огромный список. Затем, когда выполняется «поиск», поиск проверяет предварительно созданный индекс и выдает наиболее релевантные результаты, то есть результаты в верхней части списка.
Почему они ценны?
С самых ранних дней такие поисковые системы, как Lycos, Alta Vista, Yahoo! вплоть до более поздних версий Bing и Google , по сути, использовали веб-сканеры для определения своего существования.
Короче говоря, веб-сканеры являются их единственным смыслом существования. Бесчисленные боты используются для опроса каждого сайта в Интернете - по меньшей мере, геркулесовой задачей, но, тем не менее, невероятно прибыльной. Просто спросите мистера Пейджа или мистера Брина. Тем не менее, ничто не мешает вам использовать их технологии в ваших интересах.
Что является недостатком?
В идеальном мире владелец страницы веб-сайта может указать точные ключевые слова и понятия, в соответствии с которыми страница будет проиндексирована. Этот факт, конечно же, был серьезно искажен недобросовестными поставщиками SEO, которые хотят попробовать игровую систему. Бесчисленные сайты наполнили свои страницы такими фразами, как «Gangnam Style», «Mila Kunis» и «Hilary Clinton», чтобы просто увеличить свой веб-трафик.
Хорошо это или плохо, но сейчас эта тактика - образ жизни для обычного промоутера веб-сайта «черная шляпа». Слово предупреждения - держись подальше от них.
Как на самом деле работают веб-сканеры?
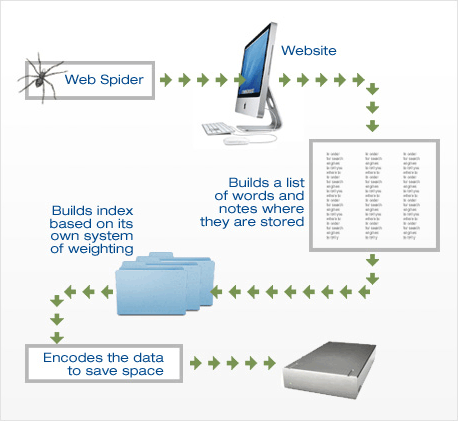
Первое нападение на веб-сайт всегда веб-сканер , В своей простейшей форме он просто каталогизирует все на сайте. Законные компании, которые «сканируются», знают об этом и хотели бы предоставить как можно больше информации. Цель состоит в том, чтобы обеспечить доступ к как можно большему количеству страниц и тем самым установить ценность сайта. Методично переходя от ссылки к ссылке, боты систематически классифицируют сайт на благо всех. Тем не менее, владелец веб-сайта или его назначенный агент обязаны использовать преимущества этой автоматической классификации.
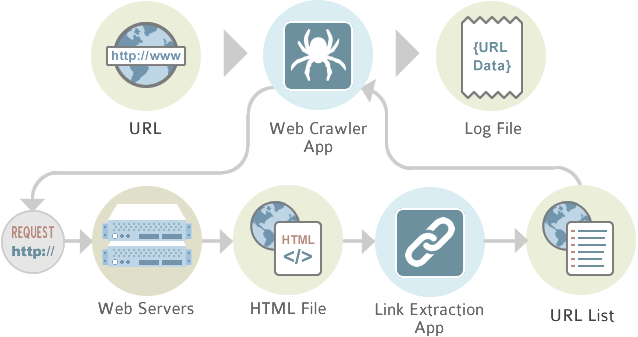
Что это действительно означает технически?
Первым шагом в этом процессе является развертывание веб-сканера для тщательного поиска по сайту. Таким образом, создается индекс слов. Важное значение в этом процессе имеет использование мета-тегов. С помощью этих «тегов» программист сайта может определить наиболее важные ключевые слова, фразы и понятия для веб-сканера и, таким образом, проиндексировать наиболее подходящим способом. Существуют также ситуации, когда владелец страницы не хочет, чтобы страница была проиндексирована, и может быть включен протокол исключения роботов, чтобы полностью отвести ботов от страницы.
Затем программа для поиска веб-страниц создает «взвешенный» индекс. Простой индекс - это просто список слов и URL - не очень хороший способ доставки полезных результатов поиска.
Вместо этого лучшие веб-сканеры используют различные факторы - например, сколько раз слово используется во всем документе, появляется ли слово в подзаголовках или если слово или фраза на самом деле в заголовке - чтобы присвоить вес слову. Затем, когда пользователь выполняет поиск, наиболее взвешенные веб-сайты будут отображаться в верхней части возвращаемых результатов.
Вы можете задаться вопросом, как поиск по всему Интернету осуществляется так эффективно. Ответ с помощью техники, известной как хеширование . Соответствующие поисковые термины на веб-сайте организованы в «хэш-таблицы», в которых используются различные ранжированные фразы и присваивается им номер. Этот процесс значительно сокращает среднее время, необходимое для поиска, даже если условия поиска несколько сложны.
Что ждет будущее веб-сканирования?
В наши дни - хотя это несколько меняется - большинство поисковых систем выполняют буквальный поиск. То есть они ищут фразы, которые пользователь вводит в запрос, как можно точнее. Кроме того, логические операторы могут использоваться довольно эффективно - если пользователь знает, что они делают - чтобы сузить поиск.
Новые версии поисковых систем - еще не выпущен - в настоящее время разрабатываются, которые будут использовать запросы на естественном языке и концепции. Результатом будут поисковые системы, которые обеспечивают лучшие результаты с меньшими усилиями, даже если пользователь действительно не знает, что они делают.
Куда я иду отсюда?
Развитие и создание интереса к вашему веб-сайту требует временных усилий и немалого опыта. Некоторые владельцы бизнеса найдут счастливую комбинацию без помощи профессиональных разработчиков веб-сайтов. Большинство других, однако, потерпит неудачу. Не делайте эту ошибку.
Однако, если в вашей команде нет веб-разработчика, вы всегда можете научиться делать это самостоятельно. Существует несколько способов управления поисковыми роботами - через файл robots.txt, теги meta robot или сторонние решения. В этой статье мы собираемся изложить все это и научить вас, как сделать это через все 3 варианта.
Как я могу контролировать веб-сканеры с Robots.txt?

Чтобы направить сканеры поисковых систем с помощью файла robots.txt, сначала вам необходимо создать файл robots.txt .
Создание или редактирование файла Robots.txt
Файл robots.txt должен находиться в корне вашего сайта. Например, если ваш домен был example.com, он должен быть найден:
На вашем сайте:
http://example.com/robots.txt
На вашем сервере:
/home/username/public_html/robots.txt
Когда поисковая система сканирует веб-сайт, она сначала запрашивает файл robots.txt, а затем следует внутренним правилам.
- Обратите внимание, что сканеры веб-сайтов не обязательно следуют правилам robots.txt, они являются лишь руководством к их поведению.
- Если вы хотите установить задержку сканирования для Google, вы должны сделать это в Инструменты Google для веб-мастеров ,
Управление доступом Web Crawler через файл Robots.txt
У вас есть несколько способов контролировать, как сканеры сканируют ваш сайт с помощью файла robots.txt, вы можете использовать:
- User-agent: определите, к какому User-agent применяется правило, и * является подстановочным знаком, соответствующим любому User-agent.
Disallow: определите, какие файлы или папки не следует сканировать.
Примеры использования Robots.txt:
Чтобы запретить сканирование всех веб-сканеров:
Вы можете запретить любой поисковой системе сканировать ваш сайт по следующим правилам:
Пользователь-агент: * Disallow: /
Чтобы разрешить полный доступ всем сканерам:
По умолчанию поисковые системы могут сканировать ваш сайт, поэтому добавление этого кода не требуется.
Пользователь-агент: * Disallow:
Чтобы запретить всем сканерам обход нескольких каталогов или страниц:
Если у вас есть несколько каталогов, таких как / cgi-bin /, / private / и / tmp /, которые вы не хотите сканировать, вы можете использовать следующий код:
Пользовательский агент: * Disallow: / cgi-bin / Disallow: / print-ready / Disallow: /refresh.htm
Вам нужно начать новую строку «Запретить» для каждого URL, который вы хотите исключить.
Чтобы исключить одного сканера:
Если вы хотите исключить только один сканер из доступа к вашему каталогу / private / и запретить все другие боты, которые вы можете использовать:
Пользователь-агент: Googlebot Disallow: /
Инструкции даны только в Google.
Чтобы разрешить доступ только одному роботу:
Если бы мы только хотели разрешить роботу Google доступ к нашему каталогу / private / и запретить все остальные боты, мы могли бы использовать:
Пользователь-агент: * Запретить: / Пользователь-агент: Googlebot Запретить:
Как видите, применяются правила специфичности, а не наследования.
Как управлять веб-сканерами с помощью метатега роботов?
Еще один способ управления поисковыми роботами через Rotats Meta Tag . Вы можете использовать этот метод, если у вас нет доступа к корневому каталогу, следовательно, вы не можете загрузить свой файл robots.txt. Также замечательно, если вы хотите запретить сканерам веб-страниц сканировать определенные страницы на вашем сайте.
Метатег Robots похож на другие Мета-теги и они добавляются в раздел <head> вашего кода.
Примеры того, как используются метатеги роботов :
Чтобы запретить всем сканерам индексировать страницу:
<meta name = "robots" content = "noindex, follow"> <meta name = "robots" content = "noindex">
Даже если сканеры не будут индексировать страницу, они все равно будут следовать ссылкам, найденным на ней.
Чтобы запретить сканерам следующие ссылки на странице:
<meta name = "robots" content = "index, nofollow"> <meta name = "robots" content = "nofollow">
Чтобы запретить сканерам сканировать и индексировать страницу и последующие страницы, на которые она ссылается:
<meta name = "robots" content = "noindex, nofollow"> <meta name = "robots" content = "none">
Чтобы поисковые системы не кэшировали вашу страницу:
<meta name = "robots" content = "noarchive">
Большинство поисковых систем кэшируют ваши ссылки в течение определенного периода времени, что может привести посетителей к более старой версии вашей страницы. Если ваша страница динамическая, вы должны использовать этот тег, чтобы поисковые системы не кэшировали вашу страницу и всегда приводили посетителей к последней версии вашей страницы.
Чтобы проиндексировать и перейти на страницу:
<meta name = "robots" content = "index, follow"> <meta name = "robots" content = "index"> <meta name = "robots" content = "follow"> <meta name = "robots" content = "все">
Эти команды инструктируют веб-сканеры индексировать страницу и переходить по ссылкам на ней. Они не нужны, потому что сканеры будут делать это по умолчанию.
Как управлять веб-сканерами без какой-либо кодировки
Изучение всех этих тегов robots.txt или мета-роботов может стать большой проблемой для небольшой задачи, особенно для людей, которые не знают, как кодировать, не имеют доступа к серверной части сайта, разработчикам, которые управляют тысячами страниц. в то же время и т. д.
Тем не менее, то, что нужно сделать, нужно сделать, указав сканерам, что делать, нельзя пропустить. Сейчас не так много решений, которые могли бы автоматизировать этот процесс для вас. Именно поэтому мы включили функцию «Правила робота» в наш плагин.

С SEOPressor Connect Управление веб-сканерами так же просто, как щелчок.

SEOPressor Connect позволяет вам контролировать веб-сканеры с помощью нескольких тиков.
Все, что вам нужно сделать, это отметить нужную функцию, нажать кнопку «Обновить», и SEOPressor Connect сгенерирует коды и вставит их на ваш сайт. Эта функция не была доступна в SEOPressor v5 или более старых версиях плагина.
Наряду со многими другими функциями, они добавлены в SEOPressor Connect, так что вы можете иметь все функции в одном плагине. С SEOPressor Connect вам не нужно устанавливать множество плагинов, загромождать свой сайт WordPress и беспокоиться о проблемах несовместимости. Вы можете иметь все SEO-решения на странице в одном плагине - SEOPressor Connect ,
Другие статьи, которые вам могут понравиться:
Чжи Юань - входящий маркетолог, имеющий опыт в SEO и контент-маркетинге. Он находится в бесконечном поиске, чтобы понять тайны мира поисковых систем, а иногда и по пути в кафе-мороженое.
Похожие
Прогноз CTR: что это такое и как это работает... чтобы повысить общую рентабельность инвестиций его клиентов, и самый быстрый путь к этой цели - использование ключевых слов с высокой степенью конверсии, поэтому нам нужно понимать прогноз CTR и CTR, чтобы знать, какие ключевые слова следует задавать и продвигать вперед. , Самая большая проблема сейчас заключается в том, что CTR становится все сложнее и сложнее прогнозировать органические поиски. Для рекламных кампаний вы можете видеть все данные на своей панели Adwords, а Google и Как настроить теги Robots.txt и Meta Robots: краткое руководство
... robots.txt, тегах мета-роботов, XML-картах сайтов, микроформатах и тегах X-Robot, у вас могут возникнуть проблемы. Не паникуйте, хотя. В этой статье я расскажу, как использовать и настраивать теги robots.txt и meta robots. Я собираюсь привести несколько практических примеров. Давайте начнем! Что такое Robots.txt? Robots.txt - это текстовый файл, который используется для инструктирования роботов поисковых систем (также известных как сканеры, роботы или Что такое ключевая фраза |
Вступление: Ключевое слово и ключевые фразы используются как синонимы. В этом сообщении мы дадим вам наиболее важную информацию о ключевых фраз Определение: значимая фраза в заголовке, предметных рубриках, примечаниях к содержанию, реферате или тексте записи в онлайн-каталоге или базе данных, которая может использоваться в качестве искать термин в свободном Что такое SEO Как мне использовать это умно как предприниматель?
Что такое SEO SEO расшифровывается как «Поисковая оптимизация» или: поисковая оптимизация. Это означает, что вы улучшаете свой веб-сайт, чтобы вас лучше находили в поисковых системах, таких как Google. Другими словами: вы можете использовать SEO для большей популярности вашего сайта, а для большего количества посетителей, которые становятся клиентами, оставьте Что такое время загрузки страницы и почему это важно?
... на из ваших страниц не выглядит молниеносной, ваш клиент перейдет на более быстрые интернет-магазины, а не преобразование этих кликов в продажи вы получите плохое качество обслуживания клиентов"> Сегодня так много сайтов у них под рукой не нужно терпеть медленные сайты , Если одна из ваших страниц не выглядит молниеносной, ваш клиент перейдет Robots.txt, метатег Robots, X-Robots Tag: встряхнутый, не перемешанный
... чтобы контент наших веб-сайтов был лучше представлен в Интернете, в противном случае мы все не были бы так заинтересованы в SEO и Link-Assistant.Com группа преданных клиентов по всему миру , Однако иногда мы бы предпочли скрыть некоторые веб-страницы от индексации и включения в SERP. Например, вы определенно предпочли бы, чтобы ваши клиенты сначала прочитали коммерческую копию, а не сразу отправили ее в корзину. Или может Robots.txt: понять, что это такое и как использовать его в своей стратегии SEO
... Robots-txt-entenda-o-que-e-e-como-usa-lo-em-sua-estrat%C3%A9gia-de-SEO.jpg"> Итак, в этом посте мы поймем, что такое файл robots.txt и почему было бы интересно использовать его для блокировки страниц для Google, Bing, Yahoo! и т.д. Что такое файл robots.txt? Robots.txt - это файл с инструкциями для поисковых систем, чтобы узнать, Что такое «позиция 0» и как она влияет на мой SEO?
Задумайтесь на минуту. Какова единственная цель поисковой системы? Цель поисковой системы - предоставить вам, пользователю, наиболее актуальную и ценную информацию, которая поможет вам принять решение или ответить на вопрос. Традиционно эта информация представлена в списке веб-сайтов, которые алгоритм Google представляет как лучшую информацию. За последние несколько лет Google (и Bing) хотели, чтобы пользователи оставались без присмотра. Они добавили обзоры, списки компаний и другие результаты SEO не работает
Это выглядит как смелое утверждение: поисковая оптимизация (SEO) не работает. Но, к сожалению, подавляющее большинство того, что выдавалось за SEO, на самом деле является SEO старой школы - вещи, которые работали 5 и 10 лет назад, но сейчас полностью устарели. Старая школа SEO не только не работает, но и часто приводит к обратным результатам. Назад, когда Ларри Пейдж Поисковая оптимизация Даниэль Вейман
... написание нового веб-контента недостаточно. Вряд ли кто-то просто найдет эту информацию в интернете и использует ее контент. Зачем они? В мире миллиарды интернет-сайтов, и в вашем регионе вы обычно не одиноки в своей отрасли. Благодаря хорошему позиционированию в поисковых системах , особенно в Google, пользователи Интернета могут быть последовательно и конкретно адресованы и, таким образом, вести себя самостоятельно в Интернете. SEO помогает во многих случаях - Google: не сообщайте свои собственные внутренние ссылки
Не размещаете ли вы внутренние ссылки на вашем сайте? Если это так, вы можете удалить их, если у вас нет веских причин использовать его. Недавно nofollowing внутренние ссылки приобрели популярность, так как многие веб-мастера, которые недавно получили руководство по исходящим ссылкам, решили nofollow каждую ссылку на своих сайтах,
Комментарии
Что такое SEO-оптимизация и что это на самом деле означает?Что такое SEO-оптимизация и что это на самом деле означает? Как работает SEO оптимизация? Это все вопросы, с которыми я буду помогать вам в этом посте. SEO звучало для меня по-гречески! Когда я начал вести блог в Blogspot, я понятия не имел, что означает SEO (поисковая оптимизация рейтинга). Я никогда не слышал об этом термине раньше! Поэтому я сделал то, что многие из нас делают, когда мы впервые слышим новый термин, я притворился, что знаю, но на самом деле я понятия Не знаете, что такое файлы журналов или почему и как они могут быть важны для повышения вашей органической производительности?
Не знаете, что такое файлы журналов или почему и как они могут быть важны для повышения вашей органической производительности? Пожалуйста, проверьте наше подробное руководство , Хорошо, так что с введениями давайте застрянем в ... Начиная Настройка сайта для сканирования упрощается за 4 простых шага, второй из которых включает возможность подключения данных из различных источников: Но как это выглядит на практике, и как вы можете гарантировать, что определяемые вами правила оптимизации могут быть легко реализованы на всем вашем сайте?
Но как это выглядит на практике, и как вы можете гарантировать, что определяемые вами правила оптимизации могут быть легко реализованы на всем вашем сайте? Сайт T-Mobile является отличным примером. Посмотрите URL-адрес страницы поддержки Apple iPhone 6 компании: https://support.t-mobile.com/community/phones-tablets-devices/apple/iphone-6 Тем не менее, как Google может утверждать, что ссылка была продана, а другие исходящие ссылки на той же странице - нет?
Тем не менее, как Google может утверждать, что ссылка была продана, а другие исходящие ссылки на той же странице - нет? Есть много случаев, когда это кажется невозможным для Google ... но те, кто рискует, должны знать о рисках. Google наказание против Buzzea за продажу ссылок 29.01.2014 Мэтт Каттс продолжает свое наступление против всех форм получения ссылок, созданных в поисковой оптимизации SEO. На этот раз это французская платформа продаж товаров, спонсируемая Buzzea, включая Txt, как насчет того, чтобы рассказать нам, как использование этого файла может внести вклад в вашу стратегию SEO?
txt, как насчет того, чтобы рассказать нам, как использование этого файла может внести вклад в вашу стратегию SEO? И если у вас есть какие-либо вопросы, не стесняйтесь представить свой вопрос. Оставьте свой комментарий! Ваши цели направлены на то, чего вы можете достичь как бизнес, или они слишком сильно зависят от вещей, которые вы не можете контролировать?
Ваши цели направлены на то, чего вы можете достичь как бизнес, или они слишком сильно зависят от вещей, которые вы не можете контролировать? реалистический Постановка реалистичных целей аналогична постановке достижимых целей. Чтобы цель была реалистичной, она также должна соответствовать вашему бизнесу. Например, если вы международная компания, но все ваши цели SEO связаны с национальными или государственными ключевыми словами, это нереально для вашего бизнеса. То же Это потому, что это хорошо, или потому что звук или изображение неправильные и потеряны?
Это потому, что это хорошо, или потому что звук или изображение неправильные и потеряны? Это действительно легко проверить, вам нужно всего лишь несколько репродукций, чтобы получить достоверное среднее значение, не более 200. Каждые несколько минут проверяйте подобные вещи. Создавайте хорошие плейлисты Вероятно, это самый простой способ поделиться и предложить контент , вам просто нужно сгруппировать видео по темам, по проектам, чем больше они Пока вы заняты тем, что вы делаете лучше всего, почему бы не поручить нам управлять вашей кампанией по отправке каталогов?
Пока вы заняты тем, что вы делаете лучше всего, почему бы не поручить нам управлять вашей кампанией по отправке каталогов? Если вам нужна дополнительная информация, просто позвоните нашей дружной команде по телефону 0845 601 2237 . Нет времени поболтать? Нет проблем - вы можете отправьте нам свой запрос с вашими вопросами представления каталога тоже. Как вы думаете, люди будут иметь с вами дело только потому, что вы настроили веб-сайт и написали несколько вещей о вашем удивительном продукте или услуге?
Как вы думаете, люди будут иметь с вами дело только потому, что вы настроили веб-сайт и написали несколько вещей о вашем удивительном продукте или услуге? Ну, угадайте, что есть сотни таких компаний, как вы, чтобы ваши потенциальные клиенты и клиенты могли выбирать, и в Интернете это просто вопрос перехода с одного веб-сайта на другой. На вашем сайте, только ваш письменный текст может убедить людей иметь с вами дело. Относись к этому очень серьезно. 5. Напишите Как вы должны поступить и как это должно выглядеть, как с точки зрения поисковой системы (для рейтинга), так и с точки зрения пользователя (для конверсий)?
Как вы должны поступить и как это должно выглядеть, как с точки зрения поисковой системы (для рейтинга), так и с точки зрения пользователя (для конверсий)? Barracuda может сформулировать масштабируемую стратегию, которая удовлетворяет обоим ... и реализовать ее для вас. Стратегии создания обзора Google Отзывы, обзоры, отзывы. Eugh. Спам, открытый для троллей, трудоемкий в управлении, сложный в приобретении. Уже достаточно. К сожалению, зарывать голову в песок - это Но что это на самом деле означает?
Но что это на самом деле означает? Вы, наверное, уже догадались об основной цели этой статьи: отзывы важны для SEO рейтинга. Это только начало. Диаграммы Моза включают в себя множество различных видов сигналов обзора. Вот список того, что сигналы, и что они значат. Каждый из этих пунктов раскрывает многое о лучших методах получения отзывов. Количество отзывов - этот график довольно очевиден: чем больше обзоров, тем лучше. BrightLocal специально
Что такое веб-сканеры?
Почему они ценны?
Что является недостатком?
Как на самом деле работают веб-сканеры?
Что это действительно означает технически?
Что ждет будущее веб-сканирования?
Куда я иду отсюда?
Txt?
Почему они ценны?
Что является недостатком?