

- Машинное обучение
- Машинное обучение в поиске
- Как это влияет на SEO?
- Виртуальные помощники и голосовой поиск
- Влияние на SEO
- Обработка естественного языка
- 1. TF * IDF
- 2. Синонимы и сущность сущности
- 3. Совместное вхождение
- 4. Расстояние
- контекст
- Измерение удовлетворенности пользователей
- SEO тактика, которую эти тенденции вдохновят
- 1. Конкурентные исследования
- 2. Визуализация данных

Автор: Маша Максимава
20 сентября 2016 г.

Ах, модные слова. Мы уже давно слышали об искусственном интеллекте, машинном обучении, обработке естественного языка и тому подобном. Часто не в очень научном контексте. Иногда даже упоминается как одно и то же.
Но на самом деле, что это за вещи? Как они влияют на результаты поиска Google? И почему это вообще имеет значение?
В этой статье я собрал 5 тенденций, которые революционизируют поиск, с подробным объяснением механизмов, стоящих за каждым из них, его ролью в алгоритме ранжирования Google и влиянием, которое он может оказать на SEO.
Но прежде чем мы перейдем к пятерке, вот важное замечание: все эти пять понятий, или «трендов», не существуют изолированно и тесно взаимосвязаны в алгоритме Google. Часто я буду называть тренд чем-то, что на самом деле является лишь одной стороной явления. Я делаю это, потому что эта сторона имеет свои отличительные черты и влияет на SEO.
Давайте начнем с короля модных слов.
Машинное обучение

Увлечение Google машинным обучением уже давно; но только в 2014 году они решили попробовать и включить его в основной продукт компании - поиск - и посмотреть, как это работает.
Эксперимент оказался невероятно эффективным, и в апреле 2015 года Google объявил, что система искусственного интеллекта с машинным обучением, называемая RankBrain, теперь стала неотъемлемой частью их алгоритма ранжирования (они даже назвали его третьим по важности сигналом ранжирования).
Чтобы полностью понять влияние - и будущий потенциал - систем машинного обучения, таких как RankBrain, давайте посмотрим, как развивались технологии в целом и ИИ в частности на протяжении многих лет.
Не новость заключается в том, что с течением времени прогресс человечества происходит все быстрее и быстрее. Рэй Курцвейл из Google звонки это закон ускорения отдачи. Принцип, лежащий в основе этого, прост: более продвинутые общества - потому что они более продвинуты и уже имеют больше инструментов под рукой - имеют возможность развиваться более быстрыми темпами.

Рэй Курцвейл
Директор по проектированию, Google
Основные меры информационной технологии следуют предсказуемым и экспоненциальным траекториям.
В теории это понятно. Но когда человеческий мозг пытается предсказать, как технология будет выглядеть через несколько лет, он будет сильно преуменьшать ее. Хитрость в том, что мы, люди, по своей природе линейны - и наше восприятие технологий тоже. Поэтому, когда мы пытаемся представить, насколько технология изменится через 20 лет, мы оглянемся на 20 лет назад и представим изменение сопоставимой величины.
Например, вот как развивались вычисления с начала 20-го века и до настоящего времени.
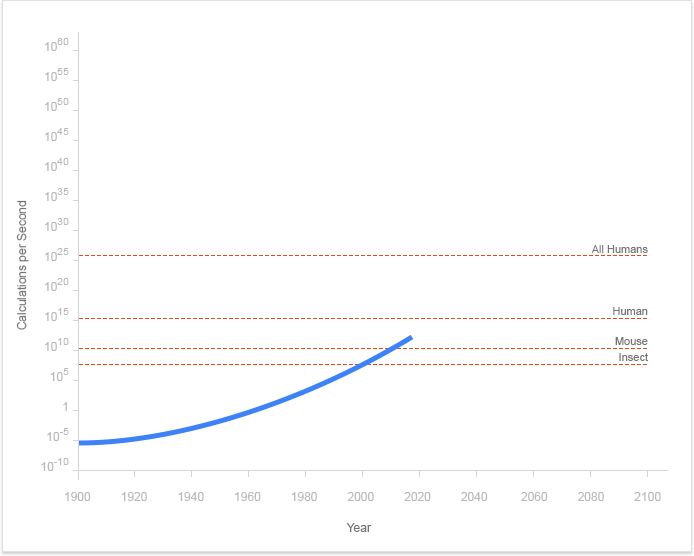
Слегка изогнутая линия на графике не совсем пугающая. За более чем сто лет разработки компьютеры (только?) Смогли достичь способности мозга мыши. Вы могли бы хорошо смотреть на график выше с доброй (но немного снисходительной) улыбкой. Молодцы компьютеры, ты победил мышь!
Но в действительности то, что выглядит как слегка изогнутая линия, является экспоненциальной функцией.
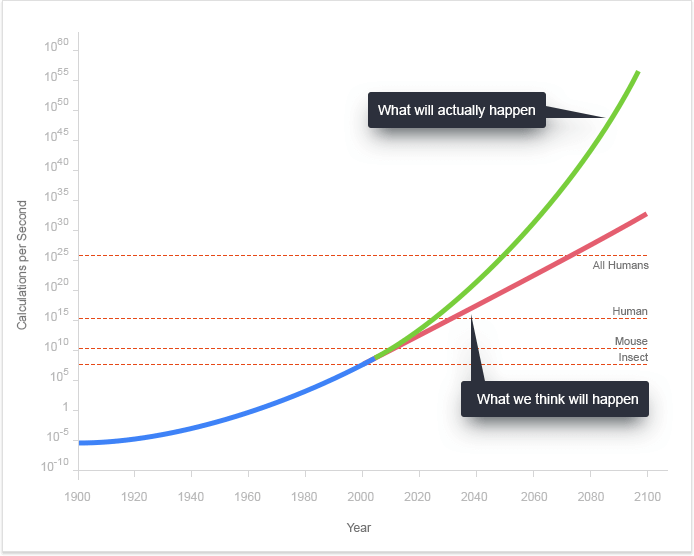
Вот еще одна визуализация экспоненциально растущей скорости, с которой развиваются технологии, что, возможно, передает сообщение еще лучше.

Машинное обучение в поиске
RankBrain, система искусственного интеллекта машинного обучения Google, помогает поисковой системе лучше интерпретировать поисковые запросы и предоставлять более релевантные результаты поиска в ответ на них. Google совершенно нечетко описывает, как работает RankBrain; но из маленьких кусочков информации Вот а также там мы можем сделать вывод, что он выполняет некоторые из следующих действий:
1. Он выясняет смысл неоднозначных запросов. Похоже, что RankBrain может выяснить значение запроса (вместо того, чтобы разбивать его на слова и искать эти слова на веб-страницах). Google Hummingbird был первым шагом к этому, и, по-видимому, RankBrain получил оттуда большую часть своих тренировочных данных. Разница в том, что RankBrain использует машинное обучение, чтобы постоянно улучшать способность понимать неоднозначные условия поиска. Скажем, когда определенный запрос вводится в строку поиска впервые, RankBrain может проводить аналогии с запросами аналогичного характера и создавать релевантные результаты поиска на основе этих аналогий.
2. Он помогает ранжировать результаты поиска, используя уникальную, специфичную для конкретной ситуации комбинацию факторов. RankBrain просматривает результаты поиска, которые, как правило, работают исключительно хорошо с поисковиками (например, те, которые получают много кликов и очень мало отказов) для данного запроса, группы запросов или ниши, а затем реверс-инжиниринг этих «лучших» результаты поиска, чтобы выяснить, какие общие черты у них есть. Используя эти идеи, он может затем сделать вывод, что для данного запроса лучше всего подходят страницы с видео-контентом и небольшим текстом, и ранжирование страниц, которые соответствуют этому описанию, выше. Для другого запроса может оказаться, что лучшие страницы почти никогда не используют фактическое ключевое слово из запроса в своем контенте, но склонны использовать сопутствующие термины a, b и ca lot. Другими словами, он определяет общие функции страниц, которые, как он знает, являются хорошими ответами на запрос, а затем ищет эти функции на других страницах.
Как это влияет на SEO?
В предыдущих обновлениях Google, будь то Panda, Penguin или Mobile (geddon), влияние каждого из них было очевидным и несколько универсальным (ваш контент должен был быть уникальным, ваши ссылки должны соответствовать определенным критериям качества, а ваш сайт - оптимизирован для мобильных устройств, если вы хотите получить рейтинг в Google Mobile).
Ситуация с RankBrain - и системами того же рода, которые последуют - противоположна. Не существует универсального способа сделать его «правильным»; вместо этого критерии ранжирования для двух разных запросов могут быть совершенно разными, что делает систему невероятно сложной для игры.
Я предсказываю, что RankBrain будет набирать еще больший импульс и играть все более важную роль в алгоритме рейтинга Google. Для SEO это означает, что эра типичных, ориентированных на поисковых роботов тактик (плотность ключевых слов, количество обратных ссылок, длина контента) окончательно необратимо закончилась. Вместо этого конкурентные исследования, вероятно, будут играть самую важную роль в каждой SEO-кампании. Маркетологи будут пытаться «эмулировать» RankBrain и смотреть на наиболее эффективные веб-страницы в данной отрасли - даже по отдельным запросам - и искать общие черты, которые разделяют эти страницы, чтобы они могли создавать контент с теми же функциями (я буду Остановимся подробнее на этом в заключительной части поста).
Виртуальные помощники и голосовой поиск

Вы вряд ли удивитесь, когда услышите, что кто-то в порядке с Google в вашем местном продуктовом магазине. Тенденция виртуального помощника - Apple Siri, Microsoft Cortana, Google Now - возможно, воспринималась как увлечение, когда она только начиналась. В основном, мы начали использовать ее не потому, что считали такую технологию полезной, а потому, что были готовы посмотреть, насколько хорошо она будет работать. («Может ли он действительно понять меня?» - Да, с частотой ошибок 8%, которая постоянно снижается. «Что, если я попробую нецензурную лексику?» - Вам скажут, что я говорю на своем языке. «Что если я говорю с шотландским акцентом? »- Совершенно хорошо, но, чтобы быть в безопасности, вы можете не говорить« одиннадцать ».)
В 2014 году тенденция буквально приняла совершенно новую форму, когда Amazon разработал Amazon Echo - устройство, эксклюзивная функция которого - быть виртуальным помощником своего владельца. Возможности Echo выходят далеко за рамки болтовни и ответов на вопросы; он может воспроизводить музыку и аудиокниги, создавать списки дел, устанавливать будильники и управлять интеллектуальными устройствами в вашем доме.
В списке виртуальных помощников Google, похоже, отстает. В отличие от Siri или Cortana, Google Now выглядит несколько безлично, и его основной функцией остается поиск вещей в Google, а не предоставление вам прямых ответов и решений.
Но если дела идут с Google, то, что они молчали о чем-то, не означает, что они не работали над этим. В мае этого года в Google I / O, компания введены помощник Google - помощник по разговорной речи, который «понимает ваш мир и помогает вам добиться цели».
Помощник Google включен в два новых продукта Google - Google Home, эхо-голосовое устройство для вашего дома и Allo, новое приложение для обмена сообщениями, которое позволяет вам взаимодействовать с помощником Google прямо в ваших чатах, либо один-на-один. Один или с друзьями ".
Я мог бы сказать это снова. Либо один на один , либо с друзьями. Google создал приложение для обмена сообщениями, которое вы можете использовать для общения с полезным роботом-тет-а-тет. Да, вроде как в "Ей" ,
Влияние на SEO
Google сообщает, что в настоящее время 55% подростков и 40% взрослых используют голосовой поиск каждый день. И это быстро растущий рынок, и соотношение голосового поиска растет быстрее, чем поиск по типу. С точки зрения SEO, запросы, сделанные голосом, отличаются от типизированных запросов. Люди не выполняют поиск с помощью своих клавиатур так же, как с голосовыми связками. Голосовой поиск - это разговорный поиск, в котором люди используют более естественные предложения вместо странного языка запросов.
Для SEO это означает, что мы должны внести коррективы не только в то, как мы проводим исследование ключевых слов, но и в язык, который мы используем при создании контента. Первым шагом к этому является понимание разговорной речи клиента. Больше, чем раньше, нам нужно провести исследование, чтобы найти фразы, которые клиенты используют для описания проблем, и взять интервью у клиентов, чтобы понять язык, который они используют, когда они говорят о теме, на которой сосредоточен наш контент.
Довольно скоро вы, вероятно, найдете потребителей, которые задают вопросы типа «Хорошо, Google! Я ищу - как бы это назвать - приложение, которое поможет мне справиться с напоминаниями и прочим». Это не будет отличным слоганом для вашего приложения, но его небольшие фрагменты могут помочь вам создать веб-копию, соответствующую языку ваших клиентов.
С виртуальными помощниками все немного сложнее. Сири, Кортана, а теперь и помощник Google можно использовать для поиска вещей в Интернете; но их более важная функция - делать вещи для людей, а не представлять им список возможных решений.
Сундар Пичаи
Генеральный директор, Google
Вы можете сказать Google: «Что играет сегодня вечером?». Сегодня, благодаря распознаванию голоса и обработке естественного языка, мы понимаем, что вы, вероятно, говорите о фильмах. Вы можете вообразить, что со временем сделаете шаг вперед. Если я попрошу об этом в пятницу, чтобы у вас был контекст, который, возможно, я хочу посмотреть со своей семьей, и дам вам три фильма, которые вам могут понравиться. Тогда я могу сказать: «Книга Джунглей хороша?». Тогда я могу попросить его забрать билеты. На следующий день я могу взять трубку, и Google скажет: «До фильмов осталось несколько часов, и ваши билеты уже здесь».
До сих пор, похоже, что вещи, которые виртуальные помощники будут в состоянии делать (поиск и бронирование ресторана, покупка билетов в кино и т. Д.), Все еще будут в значительной степени основываться на поиске, открывая новый рынок для SEO - тот, где мы будем конкурировать, чтобы стать сервисом, который виртуальные помощники могут легко использовать для выполнения задач.
Обработка естественного языка

Дайте компьютеру кусок текста, и, скорее всего, он будет иметь мало смысла. Скажем, вы подаете эту статью в систему языковой обработки. Он просматривает слова и фразы внутри него и подсчитывает, как часто каждое из них используется, вычисляя что-то, называемое «частотой термина» или TF для краткости.
Можно разумно заключить, что я использую термин «ИИ» 7 раз, а слово «часть» - 10 раз. Какой из них более важен для статьи? Как компьютер узнает, о чем на самом деле статья?
Вот тут-то и начинается машинное обучение (да, опять же). Системы понимания языка обучаются на больших массивах данных, таких как «New York Times» от Google, аннотированный корпус - набор из 1,8 миллиона статей, охватывающих 20 лет. Изучая большой набор данных текста по широкому кругу тем, эти системы могут изучать всевозможные вещи о тексте и в конечном итоге выяснять, о чем идет речь.
Есть ряд факторов, которые помогают поисковым системам обрабатывать и понимать текст.
1. TF * IDF
TF * IDF означает «частота - обратная частота документа». Он давно используется для индексации веб-страниц. Метрика измеряет важность данного ключевого слова или ключевой фразы в данном фрагменте контента.
Термин «частота» - это именно то, что подразумевает название - количество раз, когда данное слово появляется в документе, деленное на количество слов в документе. Например, в этой статье TF для «AI» и «part» будет рассчитываться следующим образом:
TF ("AI") = 7/4096 = 0,00170898
TF («часть») = 10/4096 = 0,00244141
Частота обратных документов - это мера того, насколько часто (или редко) термин встречается во всех документах, используется для уменьшения веса терминов, которые встречаются в наборе данных очень часто, и увеличения веса терминов, встречающихся редко. Для Google этот набор данных будет Интернетом; ради этого эксперимента я посмотрю два термина, которые я анализирую в Google Ngram Viewer ,
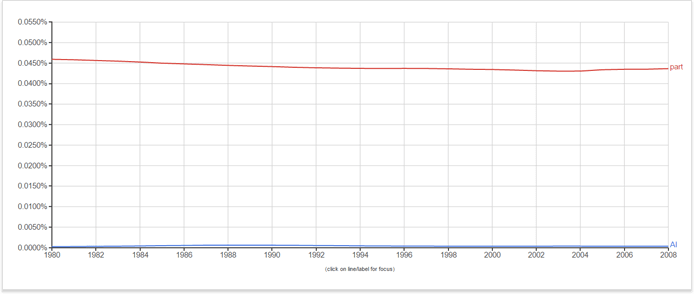
Основываясь на этих данных, давайте предположим, что у нас есть коллекция из 1 000 000 документов, около 3 из которых содержат термин «AI», а 400 из которых содержат термин «часть».
Чтобы рассчитать частоту обратных документов, нам нужно разделить общее количество документов в нашем наборе данных на количество документов, содержащих анализируемый термин, а затем взять натуральный логарифм этого числа.
ИДФ («ИИ») = ln (1 000 000/3) ≈ 12,71689827
IDF («часть») = ln (1 000 000/400) ≈ 7,82404601
Наконец, давайте продолжим и найдем TF * IDF для обоих терминов.
(TF * IDF) («AI») = 0,00170898 * 12,71689827 ≈ 0,02173292
(TF * IDF) («часть») = 0,00244141 * 7,82404601 ≈ 0,0191017
Как вы можете видеть, хотя первый термин используется меньше, чем второй, его TF * IDF выше, поскольку он встречается реже в других документах. Таким образом, мы можем сказать, что статья больше о «ИИ», чем о «деталях».
TF * IDF - отличный способ узнать, насколько заметен термин на вашей странице; и так как мы знать для факта, что Google использует это, это может быть невероятно полезно, чтобы помочь маркетологам понять, насколько релевантный определенный фрагмент контента может быть рассмотрен для данного запроса.
Но если вы внимательно следите за расчетами, возможно, вы обнаружили проблему в формуле. Правда, вы можете искусственно увеличить TF вашего контента, используя одержимое ключевое слово снова и снова; это, в свою очередь, приведет к увеличению TF * IDF. Именно поэтому эта формула используется только в качестве основы для определения релевантности; затем другие факторы вступают.
2. Синонимы и сущность сущности
Google отчеты эти синонимы играют роль в 70% поисков. Поисковая система имеет сложную систему синонимов, накопленную за 10 лет исследований. Первоначально система была основана главным образом на данных из словарей; теперь, когда машинное обучение берет на себя несколько статичный традиционный подход, оно все больше основывается на информации, которую Google узнает (как о поисковиках, так и о веб-страницах) на ходу, когда обрабатывает запросы. Интересно, что поисковая система также рисует синонимы из якорного текста обратных ссылок документа.
Система синонимов позволяет Google сопоставлять документы с запросами, даже если поисковики используют слова, отличные от заданной веб-страницы. Это особенно хорошо работает для «сущностей», где Google знает несколько альтернативных имен для одной и той же концепции. Попробуйте выполнить поиск "big blue" на Google.com, и вы поймете, что я имею в виду.
3. Совместное вхождение
Совместное вхождение часто имеет непосредственное отношение к синонимам и связанным с ними терминам и помогает Google сузить широкую тему страницы до более конкретной направленности. Это также помогает решить проблему устранения неоднозначности для запросов, в которых одно и то же ключевое слово может относиться к нескольким концепциям.
Скажем, если страница о «Java», а также упоминает такие термины, как «остров», «Индонезия», «Джакарта», «население», Google разумно решит, что страница относится к острову Ява. С другой стороны, если он включает такие понятия, как «программирование», «JVM», «программное обеспечение», «компьютер» и т. Д., Это может указывать на то, что это, вероятно, язык программирования.
В некоторой степени совместное использование также помогает Google определить качество контента с точки зрения того, насколько хорошо он раскрывает тему или отвечает на вопрос. Скажем, если вы ищете «Скарлетт Йоханссон», Google может найти страницу, которая также упоминает связанные термины, такие как названия фильмов, в которых снималась актриса, ее дата и город рождения, награды, которые она получила, и т. Д. Если страница делает не упоминая эти сопутствующие термины и вместо этого содержит имена других актеров и актрис, он, вероятно, не обладает подробной информацией, которую ищет искатель, и, следовательно, может занимать более низкое место.
4. Расстояние
Физическое расстояние между определенными словами в документе также может указывать, насколько они связаны, но оно не работает универсальным образом для всех элементов страницы. Есть также концепция семантической дистанции - способ выяснить отношения между парой слов. Например, термины в заголовках и заголовках страниц могут быть физически очень далеки от определенного слова в конце статьи; но семантически они считаются столь же близкими к нему, как и к любому другому слову в этой статье. Точно так же концепции, обсуждаемые в списках, считаются одинаково семантически близкими друг к другу, независимо от порядка их появления.
контекст

В изоляции почти каждый поисковый запрос сбивает с толку. Чтобы понять, что вы действительно ищете, когда вы что-то ищете, Google может использовать разные аспекты того, что он знает о вас - как поисковик, пользователь Интернета и как человек.
Персонализация не совсем новая концепция в SEO. Мы привыкли к пониманию того, что наша история поиска и просмотра играет определенную роль в результатах, которые мы получаем. И есть вероятность, что способы, которыми Google использует «контекст» для изменения результатов поиска, будут становиться все более сложными.
Это уже начало происходить. Например, если вы ищете «Zara», вы можете получить общую информацию о бренде и бесконечный список магазинов со всего мира. Но если вы сначала ищете «Лондон», а затем «Зара», поисковая система запомнит, что вы только что смотрели на Лондон, и автоматически сузит результаты до этой области.
Вот еще один пример. Если вы просматриваете сообщение Facebook на телефоне Android и, удерживая нажатой кнопку «Домой», активируете голосовой поиск, Google отсканирует просматриваемый вами контент, чтобы найти нужную информацию без Вы должны копировать и вставлять вещи вокруг.
Тогда, конечно, есть место. Не новость, что Google будет часто корректировать результаты поиска для вас в зависимости от того, где вы находитесь; но он также научился использовать местоположение искателя более сложными способами. Теперь, если вы находитесь на улице со своим смартфоном, вы можете спросить Google: "Что это за здание?" или "Что это за ресторан?" - и он будет искать это для вас, используя ваше местоположение как своего рода контекст.
Со временем осведомленность о местоположении, вероятно, станет еще более мощной. Бехшад Бехзади, директор Google по поисковым инновациям в цюрихской лаборатории, упомянутый что компания стремится сделать использование местоположения поисковиков более активным, что, например, позволит вам получать оповещения о том, что можно увидеть, или о событиях, которые можно посетить поблизости, когда вы отправляетесь на прогулку.
Измерение удовлетворенности пользователей

Google измеряет эффективность каждого изменения алгоритма ранжирования, которое они тестируют, с точки зрения того, что они называют «метриками». Эти метрики являются различными сигналами удовлетворенности пользователей; простыми примерами этого являются рейтинг кликов в поисковой выдаче и «заедание» (что происходит, когда поисковик нажимает на результат поиска, а затем быстро отскакивает назад). Но есть и более сложные, научно-фантастические метрики, которые Google может вскоре начать изучать. Такие как выражения лица искателей.
Один В недавних патентах Google описывается технология, которая изменяет рейтинг результатов поиска с использованием «биометрических показателей удовлетворенности пользователей» (или неудовлетворенности) определенным результатом. Эти индикаторы будут зафиксированы с помощью камеры телефона искателя, как показано на этом рисунке:
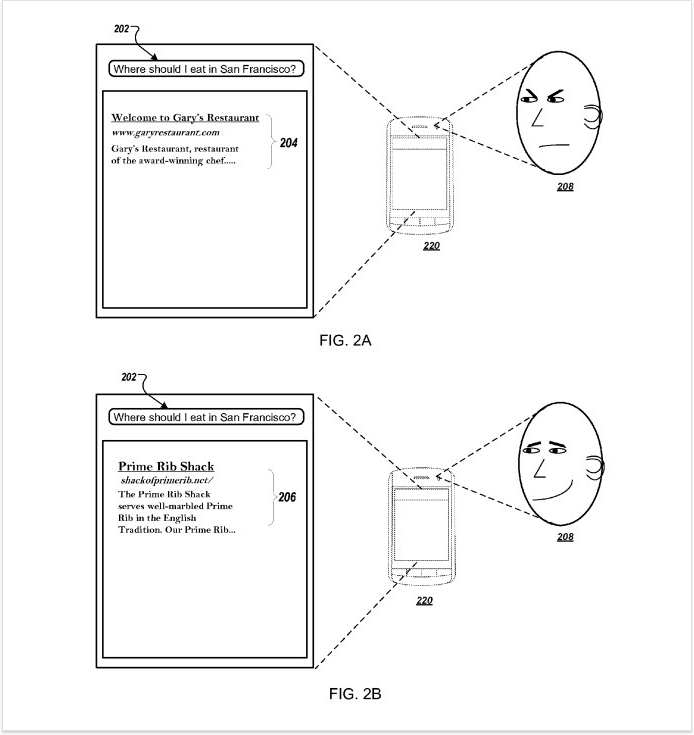
Допустим, вы ищете "рестораны Сан-Франциско" на своем мобильном телефоне. Лучший результат - ресторан, в котором вы были раньше и который вам не понравился (так что вы можете инстинктивно нахмуриться, увидев список). Это фиксируется камерой вашего телефона и воспринимается поисковым движком как негативный сигнал, что потенциально может привести к падению ресторана в результатах поиска.
Напротив, если ваша реакция на результат поиска подразумевает, что вы «любите его», Google может расценить это как положительный сигнал и впоследствии повысить рейтинг соответствующего вопроса.
Но подождите, это еще не все. В дополнение к выражению вашего лица, Google может также начать использовать телефоны поисковиков для измерения таких вещей, как температура тела и частота сердечных сокращений, которые также могут передавать эмоции (или так думают):
Определение того, что один или несколько биометрических параметров указывают на вероятное отрицательное взаимодействие пользователя с первым результатом поиска, включает в себя обнаружение повышенной температуры тела, обнаружение расширения зрачка, обнаружение подергивания глаза, обнаружение покраснения лица, обнаружение уменьшенной частоты мигания или обнаружение увеличенной частоты сердечных сокращений ,
SEO тактика, которую эти тенденции вдохновят
Google был пионером во многих технологических достижениях, которые мы видели недавно. Поскольку поиск является основным «продуктом» Google, справедливо то, что SEO развивается так же быстро.
SEO все чаще называют сложной наукой, а не маркетинговой стратегией. При выполнении SEO-анализа необходимо учитывать все больше и больше точек данных, многие из которых, как мы выяснили, могут сильно различаться от запроса к запросу.
Это делает большинство «быстрых SEO-исправлений» старой школы бесполезными в лучшем случае и вредными в худшем. Итак, если нет универсальных тестов для сравнения ваших показателей, что вы делаете?
Я держу пари, что оптимизаторы все чаще обращаются к следующим двум тактикам.
1. Конкурентные исследования
Мы слышали это некоторое время: вы должны создавать контент для людей, а не для ботов. В этом есть правда. Поисковые системы становятся все более похожими на людей - так что вы должны сделать свой контент максимально привлекательным для живых существ. Вы должны сделать это идеальным поисковиком.
Но есть еще важный вопрос, на который вы должны ответить: что действительно ищут искатели?
Чтобы выяснить это, вы обращаетесь к - как вы уже догадались - поисковым системам. Это своего рода петля. Технологии машинного обучения поисковых систем, такие как RankBrain, уже знают, что ищут поисковики, и они используют эти данные для ранжирования страниц в поисковой выдаче. Таким образом, ваша задача состоит в том, чтобы провести реинжиниринг ваших конкурентов высшего ранга (эмулировать RankBrain, если хотите) и искать общие черты в их контенте, чтобы вы могли создавать контент, отвечающий всем критериям.
Для этого вам нужна аналитика SERP. В SEO PowerSuite's Отслеживание ранга Например, мы называем это «История SERP» - архив 30 лучших результатов поиска для каждой проверки рейтинга (для сохранения истории SERP вам потребуется Лицензионный ключ Rank Tracker ).
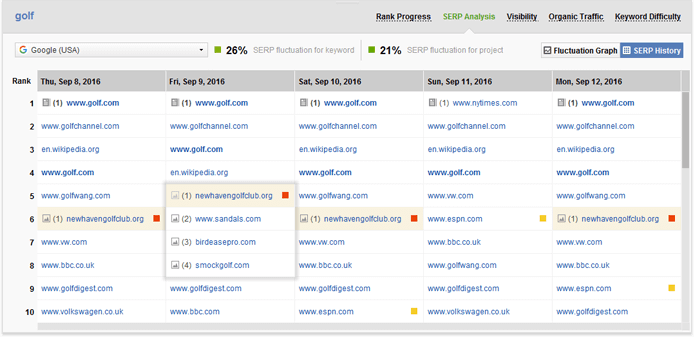
Этот вид анализа позволяет увидеть, как таблица лидеров SERP менялась с течением времени. Детальное изучение этих конкурентов и поиск общих функций в их контенте - это способ определения факторов, которые работают для конкретного ключевого слова или отрасли.
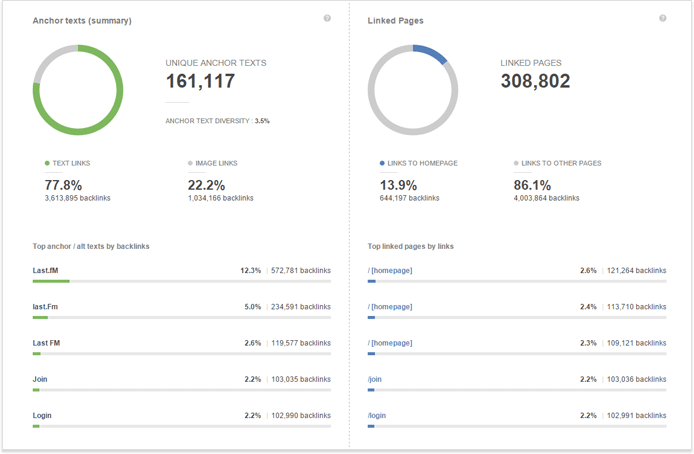
Точно так же SEO PowerSuite's SEO SpyGlass позволяет сравнить ваш профиль ссылки с конкурентами (1 участник в бесплатная версия 5 в профессиональный и 10 в предприятие ) и детально проанализировать профиль обратных ссылок каждого конкурента, чтобы выяснить, какой тип профилей ссылок (например, с точки зрения разнообразия якорного текста) будет наиболее эффективным в вашей отрасли.
2. Визуализация данных
По мере того как технология, лежащая в основе поиска, становится все более продвинутой, показатели, которые вы анализируете для SEO, становятся все более многочисленными и сложными. Чтобы разобраться во всех этих сложных данных, SEO-специалистам неизбежно понадобятся инструменты визуализации (особенно, если вы думаете о представлении все более сложных данных клиентам).
Вот пример. Допустим, вы используете Ранкер трекер История поисковой выдачи архивы, чтобы выяснить факторы, которые имеют значение в вашей отрасли. Допустим, вы проанализировали таблицу лидеров и включили эти идеи в свой контент.
Но, конечно, вы не можете остановиться там. Системы машинного обучения непрерывно получают данные обучения, а это означает, что вес определенных факторов ранжирования для данного запроса может измениться, как только это будет диктоваться показателями поведения пользователя.
Допустим, у вас есть пост о 5 инновационных тенденциях SEO, которые навсегда изменят будущее SEO, и вы хотите, чтобы этот пост занимал место по ряду ключевых слов в Google. Вы проанализировали конкурентов и выяснили, что длинный контент с визуальными элементами и, скажем, вашим основным ключевым словом в теге title имеет тенденцию занимать лучшие места; так что вы продолжаете и включаете все эти вещи на своей странице.
Чуть позже кто-то внезапно придумал способ объяснить все эти футуристические тренды в SEO очень простым способом и в виде части контента, которая значительно короче. И искателям очень нравится это короткое объяснение. Google отмечает, что неожиданно длина вашего контента, которая давала вам преимущество в поиске, работает против вас.
Очевидно, что вы не сможете контролировать это вручную и быстро обнаружить эти изменения. Вот где визуализация может оказать огромную помощь. Если вы посмотрите на график колебаний SERP в Отслеживание ранга вы сможете мгновенно определить важные изменения в результатах поиска, которые требуют вашего немедленного внимания. График измеряет разницу между 30 лучшими результатами поиска по каждому ключевому слову во время каждой проверки рейтинга. Красные всплески на графике мгновенно сообщат вам о важных изменениях в поисковой выдаче, которые вам необходимо изучить.
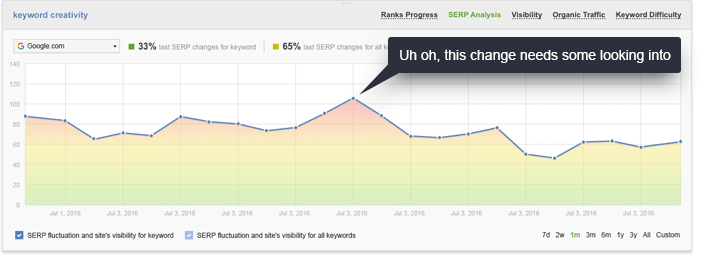
Визуализация будет работать одинаково хорошо буквально в любом аспекте SEO - особенно если вы сочетаете это с глубоким конкурентным анализом. Это выигрышная комбинация, которая поможет вам определить тенденции поиска, выбрать наиболее важные аспекты, на которых следует сосредоточиться, и, если вы будете заниматься SEO для клиентов, объяснить им расширенные концепции интуитивно простым способом.
Как всегда, жду ваших мыслей и вопросов в комментариях. Каковы ваши прогнозы на будущее поиска? Как вы думаете, какие факторы будут продолжать играть важную роль в SEO, а какие постепенно исчезнут? Пожалуйста, поделитесь своими идеями ниже.
 От: Маша Максимава
От: Маша Максимава
PS: как насчет чата лично? Команда SEO PowerSuite и я будем присутствовать SMX East в Нью-Йорке 27-29 сентября 2016 года. В повестке дня этого года более 50 новых сессий, посвященных инновационной тактике в области поисковой оптимизации (SEO), платного поиска (PPC), мобильных устройств и многого другого. Если вы собираетесь (а вы действительно, действительно должны), зайдите на стенд SEO PowerSuite, чтобы спросить нас об инструментах или SEO в целом, получить быструю демонстрацию SEO PowerSuite или даже просто сказать привет :)

Похожие
Как измерить влияние SEO... seo-1.jpg" alt="Один из вопросов, которые я неизменно получаю после выступления с речью об измерении: «А как же SEO"> Один из вопросов, которые я неизменно получаю после выступления с речью об измерении: «А как же SEO?» SEO означает «поисковая оптимизация». Посмотрите это отличное видео объяснение, если вы понятия не имеете, о чем я говорю. По сути, SEO и SEM (маркетинг в поисковых системах) - это процесс Милуоки SEO
Нужна SEO в Милуоки для вашего бизнеса? (262) 207-4396 Вы ищете профессиональное SEO агентство в Милуоки? Если это так, то мы являемся ведущей SEO-компанией, обслуживающей Милуоки, Wi. Город Милуоки известен своими пивоваренными традициями. Население города составляет 595 070 человек (2016 год) Брайтон SEO 2012
... нам чашку чая"> Брайтон SEO «Кэт, приготовь нам чашку чая? Если вы сделаете нам чашку чая, я уберу мусор после телевизионной программы » Дейв Тротт , В приведенном выше предложении есть все, что вам нужно знать о рекламе. Это все там, часть меня испытывает желание закончить эту запись в блоге здесь и позволить вам распутать вещи ... Но я SEO Консалтинг
... инга предназначена для крупных компаний, которые уже имеют внутреннюю маркетинговую команду, но не знакомы с лучшими практиками и стратегиями SEO. Мы пойдем вместе с вашей нынешней командой и поможем проконсультировать и обучить их тому, как органично развивать свой веб-сайт и генерировать эффективные лиды через электронный маркетинг. В Profitworks мы являемся командой экспертов по маркетингу и поисковой оптимизации (SEO). Мы специализируемся на том, чтобы веб-сайты наших клиентов поднимались Канзас-Сити SEO
Ищете эксперта в Канзас-Сити SEO? Сделайте свой бизнес веб-сайт выделиться в крупных городах США Получите отзывчивый сайт с высоким трафиком, вознагражденный Google Найдите в Интернете то, что вы делаете, увеличьте свою экспозицию Развивайте свой бренд и SEO обучение онлайн в Индии
... SEO-training-online-in-India1.jpg"> SEO обучение онлайн в Индии Если вы ищете SEO обучение онлайн в Индии, то не нужно искать дальше. Мы предлагаем обучение в классе и онлайн. Мы предлагаем обучение в классе в Бангалоре. Мы предлагаем онлайн-обучение по скайпу. Мы предлагаем онлайн-обучение на английском языке для иностранных студентов, а для индийских студентов мы предлагаем обучение Последний Seo 2018 Seo Конкурс Info99
Для тех из вас, кто хочет принять участие в этом SEO конкурсе, вы можете создавать статьи с темами Альтернативный агент Link Link Poker - 99 В последнем апрельском конкурсе SEO за 2018 год есть ряд положений, которые приведены ниже. Что такое SEO Как мне использовать это умно как предприниматель?
... начает, что вы улучшаете свой веб-сайт, чтобы вас лучше находили в поисковых системах, таких как Google. Другими словами: вы можете использовать SEO для большей популярности вашего сайта, а для большего количества посетителей, которые становятся клиентами, оставьте контактную информацию с вами или подпишитесь на рассылку. Например, рассмотрим владельца кафе, который устраивает вечеринку на следующих выходных и нуждается в дополнительном запасе кубиков льда. Предположим, вы являетесь поставщиком Как Tumblr может повлиять на SEO
... ие к тому, чтобы быть немного ботаником (который они называют новым черным), я - также давний блоггер"> В дополнение к тому, чтобы быть немного ботаником (который они называют новым черным), я - также давний блоггер. Мой последний блог-проект - это блог о моде, и мне очень понравилось создавать сайт и создавать что-то вроде сообщества. И да, парень может вести / вести блог о моде. Во всяком случае, некоторое время назад я случайно обнаружил, как Tumblr может повлиять на SEO Как оптимизировать YouTube видео для SEO
Поскольку поисковые системы не могут смотреть и понимать видео (по крайней мере, пока), важно научиться оптимизировать видео YouTube для SEO. С четкой стратегией оптимизации видео алгоритмы, которые находят и оценивают видео, будут лучше идентифицировать ваш контент как релевантный. Для этого я расскажу о трех вещах, которые вы можете сделать, чтобы оптимизировать видео YouTube для SEO. Исследования, исследования, исследования Одна из основных ценностей Funnelbox - «предвидеть Поиск маркетинговых услуг
Услуги по поисковому маркетингу могут работать в разных категориях, таких как платный поиск или AdWords, органическая поисковая оптимизация и управление покупками Поскольку большинство интернет-пользователей начинают поиски продуктов или услуг с поисковой системы, размещаемой на первой странице, они стали более важными, чем когда-либо. Ознакомьтесь с нашими службами поискового маркетинга ниже и нажмите на конкретную услугу, чтобы узнать больше.
Комментарии
Как вы должны поступить и как это должно выглядеть, как с точки зрения поисковой системы (для рейтинга), так и с точки зрения пользователя (для конверсий)?Как вы должны поступить и как это должно выглядеть, как с точки зрения поисковой системы (для рейтинга), так и с точки зрения пользователя (для конверсий)? Barracuda может сформулировать масштабируемую стратегию, которая удовлетворяет обоим ... и реализовать ее для вас. Стратегии создания обзора Google Отзывы, обзоры, отзывы. Eugh. Спам, открытый для троллей, трудоемкий в управлении, сложный в приобретении. Уже достаточно. К сожалению, зарывать голову в песок - это XGen SEO Обзор - Как работает это программное обеспечение SEO?
Как вы должны поступить и как это должно выглядеть, как с точки зрения поисковой системы (для рейтинга), так и с точки зрения пользователя (для конверсий)? Barracuda может сформулировать масштабируемую стратегию, которая удовлетворяет обоим ... и реализовать ее для вас. Стратегии создания обзора Google Отзывы, обзоры, отзывы. Eugh. Спам, открытый для троллей, трудоемкий в управлении, сложный в приобретении. Уже достаточно. К сожалению, зарывать голову в песок - это Один из вопросов, которые я неизменно получаю после выступления с речью об измерении: «А как же SEO?
Один из вопросов, которые я неизменно получаю после выступления с речью об измерении: «А как же SEO?» SEO означает «поисковая оптимизация». Посмотрите это отличное видео объяснение, если вы понятия не имеете, о чем я говорю. По сути, SEO и SEM (маркетинг в поисковых системах) - это процесс определения правильных слов, изображений, заголовков и ссылок в вашем контенте, чтобы он попадал в верхнюю часть страницы, когда Но как это выглядит на практике, и как вы можете гарантировать, что определяемые вами правила оптимизации могут быть легко реализованы на всем вашем сайте?
Но как это выглядит на практике, и как вы можете гарантировать, что определяемые вами правила оптимизации могут быть легко реализованы на всем вашем сайте? Сайт T-Mobile является отличным примером. Посмотрите URL-адрес страницы поддержки Apple iPhone 6 компании: https://support.t-mobile.com/community/phones-tablets-devices/apple/iphone-6 Txt, как насчет того, чтобы рассказать нам, как использование этого файла может внести вклад в вашу стратегию SEO?
txt, как насчет того, чтобы рассказать нам, как использование этого файла может внести вклад в вашу стратегию SEO? И если у вас есть какие-либо вопросы, не стесняйтесь представить свой вопрос. Оставьте свой комментарий! Итак, как владелец малого бизнеса, как вы можете настроить свою локальную стратегию SEO с помощью WordPress?
Итак, как владелец малого бизнеса, как вы можете настроить свою локальную стратегию SEO с помощью WordPress? Сделайте так, чтобы клиенты (и поисковые системы) легко подключали ваши услуги к определенному местоположению . Это низко висящий фрукт, но вы будете удивлены, как много ваших конкурентов не делают этого. Скажем, например, вы финансовый консультант с несколькими офисами на Среднем Западе. Клиент из Иллинойса может захотеть узнать, дает ли ваша команда А как насчет нейтральных, которые не помогают, но не влияют на рейтинг вашего сайта и SEO?
А как насчет нейтральных, которые не помогают, но не влияют на рейтинг вашего сайта и SEO? Нейтральные обратные ссылки могут не дать вашему веб-сайту необходимую поддержку SEO, но они также не будут подвергать ваш сайт потенциально суровым штрафам Google. Фактически, с обновлением Google Penguin, некоторые штрафы за плохие обратные ссылки, потому что поисковая система поняла, что сами сайты не имеют контроля над каждым сайтом, который ссылается на их. В результате, Итак, как они это сделали?
Итак, как они это сделали? Исследование рогатки SEO Optify Предполагается, что все поиски привели к началу 20 кликов, а Где скрыты эти секреты SEO, эти мастер-трюки?
Где скрыты эти секреты SEO, эти мастер-трюки? В блоге Google для веб-мастеров и видео. Этот пост является лишь кратким изложением их основных инструкций. Google буквально просит вас сделать это. Качество и видимость. Это действительно великий секрет SEO и контента. Если у вас есть большие секреты SEO, пожалуйста, оставьте их в комментариях ниже. SEO советы , Они будут вводить поисковые запросы, такие как «как мне получить мой сайт выше в гугле ?
Где скрыты эти секреты SEO, эти мастер-трюки? В блоге Google для веб-мастеров и видео. Этот пост является лишь кратким изложением их основных инструкций. Google буквально просит вас сделать это. Качество и видимость. Это действительно великий секрет SEO и контента. Если у вас есть большие секреты SEO, пожалуйста, оставьте их в комментариях ниже. Как новые медиа, такие как веб-сайты, сайты социальных сетей, такие как Facebook, Twitter или Snapchat, бросают вызов традиционным идеям маркетинга?
Как новые медиа, такие как веб-сайты, сайты социальных сетей, такие как Facebook, Twitter или Snapchat, бросают вызов традиционным идеям маркетинга? Каким образом колледжи или университеты должны адаптировать свои методики преподавания, чтобы лучше подготовить специалиста по маркетингу для Нового мира интернет-маркетинга в Интернете, социальных сетях и мобильного маркетинга? Какие существующие маркетинговые концепции остаются важными, какие становятся неактуальными, и какие новые
Но на самом деле, что это за вещи?
Как они влияют на результаты поиска Google?
И почему это вообще имеет значение?
Олько?
Как это влияет на SEO?
«Может ли он действительно понять меня?
«Что, если я попробую нецензурную лексику?
«Что если я говорю с шотландским акцентом?
Тогда я могу сказать: «Книга Джунглей хороша?
Какой из них более важен для статьи?